Reading Minutes for Effective Modern C++
This is for taking the notes when reading Effective Modern C++ by Scott Meyers.
Errata Page
This is the Errata Page
Words
Vocabulary
coax /kəʊks/ *v.*哄,劝诱;连哄带劝地得到;小心地摆弄(机器或装置)
turf
indebted
exasperation
pervasive
heuristic
**variadic **
steer clear of 避开; 躲避; 绕开;
tyranny 暴虐,专横
reason about 推出
all but impossible 几乎不可能
enigmatic 神秘的;高深莫测的;谜一般的
hard-pressed 被紧紧追赶的;任务紧急而繁忙的;处境艰难的
hazy 雾蒙蒙的,朦胧的;记不清的,模糊的;
a pinch of 一撮,少许
adornment 装饰;装饰品(书中提到的是指一个类型的const or reference qualifiers)
niche n. 合适(称心)的工作(活动); adj. (产品)针对特定小群体的
foliage n. (植物的)枝叶,叶子
curve ball 使其很难被击打的弧线球
mondo adj. 绝对的;完全的;(非正式)非凡的,卓绝的;相当
stir up 激起;煽动;搅拌;唤起
turbidity n. [分化] 浊度;浑浊;混浊度;混乱
purview n. 范围,权限;视界;条款
as a matter of course 理所当然的(事);自然地
revelation n. 被揭示的真相,被揭露的内情;揭露,披露;出乎意料的事物,令人惊喜的发现;(上帝的)启示,默示;《启示录》(《圣经·新约》末卷,讲述上帝对圣约翰有关未来的启示)
parrot v. 机械地模仿,鹦鹉学舌般重复
compilable 可编译的
elicit v. 引出,得到;
palatable adj. 美味的,可口的;愉快的
bedevil vt. 使痛苦;虐待;使苦恼
dutifully adv. 忠实地;忠贞地;尽责地,忠诚地
ins and outs 复杂细节;进进出出;盛衰
potholes n. 凹坑;坑槽;洞坑(pothole 的复数形式)
notwithstanding prep. 虽然,尽管;*adv.*尽管如此;*conj.*虽然,尽管
amiss adj. 有毛病的,有缺陷的;出差错的;*adv.*错误地
zig n. 急转;锯齿形转角 *vi.*转弯
zag n. 急转;急变;锯齿形转角 *vi.*急转;急变;急弯
innocuous adj. 无害的;无伤大雅的
afield adv. 在远方地;遥远地;远离家乡地;在田野,在野外 *adj.*远方的;遥远的;远离家乡的
Pantheon n. 万神殿;名流群
compatriot n. 同胞,同国人;同事,伙伴
blindside v. 出其不意地袭击;(使)遭受意外的打击;拦腰撞上(其他车辆)
tip-off n. 密报;警告;举报
boast of v. 吹牛,自夸
newbie n. 网络新手;新兵
demarcate vt. 划分界线;区别
arcane adj. 神秘的,晦涩难懂的
burbling v. 语无伦次地讲话;潺潺做声;(航空)产生气流(burble 的现在分词);
n. 潺潺的水声;(诗歌)汩汩的水声;激动人心的演讲
deliberation n. 考虑,思考;从容,审慎;审议,商议;考虑,细想
unrivaled *adj. *无敌的;至高无上的;无比的
waylay vt. 伏击;埋伏
concede v. (通常指不情愿地)承认;认(输),承认(失败);授予,让与;让对手得分
consensus n. 一致看法,共识
grudge n. 怨恨,嫌隙 v. (因不满而)不愿意给(或允许);嫉恨,妒忌(某人)做成(某事)
grudgingly adv. 勉强地;不情愿地
implication n. 可能的影响(或作用、结果);含意,暗指;牵连,涉及
leeway n. 余地;风压差;偏航;落后
run-of-the-mill adj. 普通的;非精选的
run-of-the-mine adj. 普通的,不突出的;(煤)未分类的
ironclad adj. 装甲的;打不破的;坚固的; *n.*装甲舰
carpal n. 腕关节;*adj.*腕关节的
carpal tunnel syndrome 腕管综合征
cumbersome *adj. *笨重的;繁琐的,复杂的;(话语或措词)冗长的
concoct vt. 编造;调制(食物或饮品)
assortment n. 各种各样,混合
inferior adj. 次的,较差的;低等的,下级的;自卑的;(法庭,特别法庭)下级的;(商品,服务)需求量在衰退期中较之繁荣期更大的,低档的;(位置)下方的,下位的,靠下的;(字母,数字,符号)下标的;低等的;*n.*下级,(地位或成就)低于他人者;下标字母,下标数字,下标符号
belatedly adv. 延迟地;延续地
child’s play 容易干的事;轻而易举之事
travesty n. 歪曲;滑稽作品;拙劣的模仿作品;*vt.*歪曲;滑稽地模仿
wanton adj. 嬉戏的;繁茂的;荒唐的;无节制的;放纵的;n. 荡妇;水性杨花的女人 vi. 放肆;嬉戏;闲荡;vt. 挥霍
enumerator n. 人口普查员,计数员
susceptible adj. 易得病的,易受影响的;(人)易受感动的,易动感情的;可能有······的,容许······的;<正式>(尤指想法或陈述)能被理解(或证明、解释)的
nonsensical adj. 无意义的;荒谬的
tuple 美*/ˈtjʊpəl; ˈtʌpəl/* n. [计] 元组,重数
**sleek ** adj. 光滑的,光亮的;线条流畅的,造型优美的;时髦阔气的;油嘴滑舌的;*v.*使平整光亮;掩盖;打扮整洁
peasy adj. 像豌豆的;<非正式,英>容易的,简单的 (用法:Easy, peasy.)
supersede vt. 替代,取代
entail v. 使必要,需要;<旧>遗赠(财产),限定继承;使人承担
dissipate v. (使某事物)消散,消失;挥霍,耗费;放荡
dishearten vt. 使灰心,使沮丧,使气馁
kvetch n. (美)吹毛求疵的人;vi. (美)经常性地发牢骚;抱怨
gauge v. 估计,判断;测量
ramification n. 衍生物;分枝,分叉;支流;(衍生的)结果、影响
contemplate v. 沉思,深思熟虑;盘算,打算;凝视,注视;考虑接受(发生某事的可能性)
see the light of day 重见天日;问世;为公众所熟知come into existence; be made public,
halfhearted adj. 不认真的;不热心的;无兴趣的
it is anything but not at all (used for emphasis)
grisly adj. 可怕的;厉害的;严重的
contort vt. 扭曲;曲解;vi. 扭曲(Use: some amount of contorting.)
sledgehammer n. (有柄的)大锤;猛烈的打击;v. 用大锤打;猛力打;adj. 手下不留情的;强力的
eminent adj. (在某领域或职业中)卓越的,出众的;突出的,明显的
at the end of the day 最终;到头来;不管怎么说
temperamental adj. 喜怒无常的,性情多变的;气质的,性情的;(机器、汽车等)性能不稳定的,易坏的
dichotomy n. 二分法;两分;分裂;双歧分枝
unwind v. 放松,松弛;解开,展开
preeminent adj. 卓越的;超群的
roundabout adj. 绕路的,迂回的;(说话)绕圈子的,不直截了当的
bleak adj. 不乐观的,无望的;无遮掩的,荒凉的;阴冷的,寒冷的;沮丧的,阴郁的;(人或其表情)冷漠的,冷峻的
kindle v. 点燃,开始燃烧;激起,激发;(感情)激动起来;(兔)产仔;照亮,(使)发亮;着火
hoop n. (金属、木或类似材料制成的)箍,环(尤指用于箍桶或制框架);
saddle n. 鞍,马鞍;v. 使承担(责任、任务),使负重担
nuanced /ˈnuːˌɑːnst/ adj. 微妙的;具有细微差别的
intriguing adj. 非常有趣的,引人入胜的
beefed up 通常作beef up vt. 加强(增援,充实);补充(人数,兵力)等
blithely /ˈblaɪðli/ adv. 快活地;无忧无虑地
overkill n. 过犹不及,过分行为;超量毁伤
immaterial adj. 非物质的;无形的;不重要的;非实质的
parlance n. 说法;用语;语调;发言
inductee n. 应召入伍的士兵;就任者
preclude v. <正式>阻止,妨碍(preclude sb. from)
rationale n. <正式>根本原因,逻辑依据
sidestep vt. 回避;横跨一步躲避
blather v. 喋喋不休;絮絮叨叨;啰嗦地说;n. 废话;胡说
ascertain v. 查明,确定
slight adj. 轻微的,少量的;(人)瘦小的,纤弱的;不深奥的,不重要的
lapse n. 过失,小失误;(两件事发生的)间隔时间;(活动的)暂停,中断;开始说,开始做;(因未继续缴费而导致的)终止,结束; v. (时间)流逝;(合同、协议等)失效,期满终止;(状态,活动)中止,结束;背弃,放弃(宗教信仰);开始(以某种方式)说话、行事(lapse into)
ostensible adj. 表面的;假装的
co-opt vt. 由现会员选举;指派
atypical adj. 非典型的;不合规则的
frolic v. 嬉戏;调情;n. 嬉戏,嬉闹;调情;adj. 欢乐的,嬉戏的
blissful adj. 极乐的;使人幸福的;无忧无虑的;充满喜悦的
veritably adv. 真实地;真正地
bliss n. 极乐,天赐之福;天堂,乐园;v. <非正式>乐不可支,欣喜若狂
jeer v. 嘲笑;戏弄;奚落
generality n. 概论;普遍性;大部分
bravado n. 虚张声势;冒险
akin adj. 相似的,类似的;有血缘关系的
mnemonic /nɪˈmɑːnɪk/ adj. 记忆的;助记的;记忆术的
pique vt. 使愤恨,使恼怒;激起(兴趣,好奇心); 赢(某人)三十分
abomination n. 厌恶;憎恨;令人厌恶的事物
stylistic adj. 体裁上的;格式上的;文体论的
albeit conj. 虽然,尽管
wane v. (月亮)缺,亏;衰落,减少;消逝
annulment /əˈnʌlmənt/ n. 取消;废除
dispensation /ˌdɪspenˈseɪʃn/ n. 分配;免除;豁免;天命
contend v. 声称,主张;竞争,争夺;处理,对付
augmentation /ˌɔːɡmenˈteɪʃ(ə)n/ n. 增大,增多;增加物;(主旋律的)延长;(作为殊荣而对纹章进行的)扩充
clog /klɑːɡ/ v. 阻塞,堵塞;n. 木底鞋,木屐;累赘,障碍;管道堵塞物
afoul /əˈfaʊl/ adv. (与法律等)相抵触,有冲突,卷入纠缠地;adj. 冲突的,纠缠的
tenet /ˈtenɪt/ n. 原则,信条
bloat /bloʊt/ adj. 肿胀的,鼓起的;饮食过度的,胃胀的;v. 使膨胀,肿胀;腌制;溢出
conjure /ˈkɑːndʒər/ v. 变魔术,使……变戏法般地出现(或消失);想象出,设想出;使浮现于脑海,使想起;念咒召唤出(鬼魂等);<古>恳求,祈求
suffices /səˈfaɪs/ v. 足够,足以;满足……的需求;有能力
obviate /ˈɑːbvieɪt/ vt. 排除;避免;消除
syntactic /sɪnˈtæktɪk/ adj. 句法的;语法的;依据造句法的
vis-à-vis /ˌviːz ɑː ˈviː/ prep. 关于;与……比较;与……相对;adv. 面对面地;共同地;n. 相应地位的人(或群体);对手;面对面的会见
bookkeeping n. 记帐,簿记
tally /ˈtæli/ n. 记录,得分;账单;<史>符木;(对树或植物进行说明的)标志牌,标签;v. 相符,吻合;计算,合计;(在游戏或体育运动中)得分,进球
preclude v. <正式>阻止,妨碍(preclude sb. from)
hitch /hɪtʃ/ v. 搭便车(旅行),搭顺风车;拴住,套住,钩住;将(动物)套上车;提起,拉起(衣服);攀上,爬上;<非正式>结婚(get hitched);n. 临时故障,小问题;(某种)结;<美,非正式>一段服役,一段任职期;<美>(尤指机动车的拖杆)牵引装置;<非正式>免费搭便车;蹒跚
whereby adv. 凭此,借以
reek /riːk/ v. 散发臭味;带有令人不快(或不满)的内容;散发蒸汽(或浓烟);n. 臭味;烟;蒸汽;
bygone /ˈbaɪɡɔːn/ adj. 过去的;n. 过去的事
millennium /mɪˈleniəm/ n. 一千年;千周年纪念日,千禧年(the millennium);世界末日前基督治理世界的一千年(the millennium);(作为乌托邦的)美满时期,太平盛世(the millennium);(复数形式millennia或millenniums)
sully /ˈsʌli/ vt. 玷污;使丢脸;n. 污点,损伤
metaphorical /ˌmetəˈfɔːrɪkl/ adj. 隐喻的,象征的
disparate /ˈdɪspərət/ adj. 迥然不同的,无法比较的;多元的;n. 全异的东西,无法相比较的东西
proverbial /prəˈvɜːrbiəl/ adj. 谚语的,俗话所说的;众所周知的;n. (常用于委婉替代谚语或成语中未出现的词)那东西,那玩意儿
conform /kənˈfɔːrm/ v. 遵守,符合;顺从,随潮流;一致,相吻合
din /dɪn/ n. 喧嚣声,嘈杂声;宗教法律,犹太法律;(尤指伊斯兰教)宗教信仰;v. 再三叮嘱,反复教导;发出喧闹声
dispense /dɪˈspens/ v. 发放,分配;提供,施予;配(药),发(药)
yucky /ˈjʌki/ adj. 恶心的;讨人厌的;不愉快的
eschew /ɪsˈtʃuː/ vt. 避免;避开;远避
raison d’être /ˌrāzôn ˈdetrə/ n. the most important reason or purpose for someone or something’s existence.
volatile /ˈvɑːlət(ə)l/ adj. 易变的,动荡不定的,反复无常的;
idiomaticity /ˌɪdɪəʊməˈtɪsətɪ/ n. 习语性;表达习惯(某种语言的)
necessitates /nəˈsesɪteɪt/ v. 使成为必需,需要;迫使
poster child n. (公益广告中的)海报儿童;(幽默用法)榜样,典型人物
ergo /ˈerɡoʊ/ adv. 因此,所以;conj. 因此
allot /əˈlɑːt/ v. 分配,分派,划拨
finicky /ˈfɪnɪki/ adj. 过分讲究的;过分注意的;过分繁琐的
paraphrase /ˈpærəfreɪz/ n. 释义,改述;v. 释义,改述
legalistic /ˌliːɡəˈlɪstɪk/ adj. 尊重法律的
arguably /ˈɑːrɡjuəbli/ adv. 可论证地,按理
prose /proʊz/ n. 散文,白话文;(尤指待翻译的)一段散文;平淡乏味的文章(或话语,表达法);
v. 冗长乏味地说;<旧> 把……写成散文,把……改写成散文;写散文
hinder /ˈhɪndər/ v. 阻碍,妨碍;adj. (尤指身体部位)后面的
preclude /prɪˈkluːd/ v. <正式>阻止,妨碍(preclude sb. from)
topple /ˈtɑːpl/ v. (使)不稳而倒下,(使)倒塌;推翻(首领),颠覆(政权);<美>战胜,打败
banish /ˈbænɪʃ/ v. 驱逐,赶走;将……驱逐出境,流放;清除,消除;打消……的念头,驱除(想法)
exasperation /ɪɡˌzæspəˈreɪʃ(ə)n/ n. 恼怒;恶化;惹人恼怒的事
uphold v. 支持,维护(法规、制度或原则);认可,维持(法院原判);鼓励;举起
trump /trʌmp/ n. (牌戏中的一张)王牌,将牌;v. 出王牌赢(牌);赢,胜过,打败;
wrinkle /ˈrɪŋk(ə)l/ n. (皮肤上的)皱纹;(布或纸上的)皱褶; <非正式>小困难,小难题;<非正式>令人吃惊的情节,出人意料的事情;<非正式>妙计,好主意;v. (使脸上)起皱纹,皱起;(布料等)起皱,起褶
freestanding adj. 独立式的;非附属的;不需依靠支撑物的
funnel /ˈfʌn(ə)l/ n. 漏斗;漏斗状物;(船、蒸汽机车上的)烟囱;v. 通过漏斗,穿过狭窄通道;输送,传送(金钱、货物或信息);(一端逐渐扩大或收缩)形成漏斗状
recoil vi. 畏缩;弹回;报应;n. 畏缩;弹回;反作用
lest /lest/ conj. 以免,避免;唯恐,担心
sidetrack vt. 将(火车)[建] 转到侧线;转变(话题)
tumble /ˈtʌmb(ə)l/ v. 翻滚,滚落;摔倒,跌倒;
tumble into 跌入
morass /məˈræs/ n. 沼泽;困境;乱糟糟的一堆
tantamount /ˈtæntəmaʊnt/ adj. 同等的;相当于……的
immaterial /ˌɪməˈtɪriəl/ adj. 非物质的;无形的;不重要的;非实质的
droid /drɔɪd/ n. 机器人
ratchet /ˈrætʃɪt/ n. 棘轮,棘齿;救护车;vt. 安装棘齿于……
ratchet down 稳步降低; 使…稳步降低
off-putting adj. 令人不愉快的;老是推托的
boilerplate /ˈbɔɪlərpleɪt/ n. 样板文件;引用
fudge /fʌdʒ/ v. 含糊其辞,回避;篡改,捏造(事实,数字);n. 敷衍,装模作样(a fudge)
proliferation /prəˌlɪfəˈreɪʃn/ n. (数量的)激增,剧增;(细胞、组织、有机体的)繁殖,增生;大量
belay /bɪˈleɪ/ v. 把缆绳拴在系索栓上;拴住,系牢;停止
déjà 已经
déjà vu /ˌdā-ˌzhä-ˈvü/
pesky /ˈpeski/ adj. 讨厌的,麻烦的
palatable /ˈpælətəb(ə)l/ adj. 美味的,可口的;愉快的
tantalizingly /ˈtæntəlaɪzɪŋli/ adv. 逗人地;……得令人着急
savor /ˈseɪvər/ vt. 尽情享受;使有风味;加调味品于;品尝,欣赏
aroma /əˈroʊmə/ n. 芳香,浓香;(喻)气氛
voilà 那就是(源自法语)
fetish n. 恋物(等于 fetich);迷信;偶像
aplomb /əˈplɑːm/ n. 沉着;垂直;泰然自若
baffle /ˈbæf(ə)l/ v. 使困惑,难住;抑制,控制;n. 挡板,隔板,反射板
baffling /ˈbæflɪŋ/ adj. 令人困惑的;阻碍的;令人丧气的;变幻的
reprimand /ˈreprɪmænd/ n. 谴责,训斥;v. 谴责
conformant /kənˈfôrmənt/ 顺应,一致。(especially of technology) compatible or conforming with appropriate standards
shazam /ʃəˈzæm/ int. 快变(用于引入惊人的行为、故事或变化)
aura /ˈɔːrə/ n. 气氛,氛围;(据说由生物体散发出的)光影;(任何看不到的)发散物(尤指气味);(癫痫或偏头痛发作前的)先兆,预感
overhaul /ˌoʊvərˈhɔːl/ v. 彻底检修,全面改造;全面改革(制度或方法);(尤指在体育竞赛中)赶上,超过;*n.*大修,彻底检修;
caveat /ˈkæviæt/ n. <正式>警告,限制性条款;<法律>预告登记(尤指遗嘱检验中,非告知本人而不得进行某行为的通知)
glass-half-full 乐观的(非正式)
sure-fire adj. (非正式)一定能成功的
emblazon /ɪmˈbleɪzn/ vt. 颂扬;用纹章装饰
salient /ˈseɪliənt/ adj. 突出的,显著的;(角)凸出的;(纹章,动物)后腿站立前爪举起的;n. (防御工事的)凸出部分
decree /dɪˈkriː/ n. 法令,政令;裁定,判决;v. 裁定,判决,颁布
awry /əˈraɪ/ adj. 脱离既定路线的;歪的;adv. 迷途地;歪(比如,go awry)
plop /plɑːp/ v. 扑通落下;扑通一声把……放入(尤指液体);重重地坐下,躺下(比如,plop into)
adage /ˈædɪdʒ/ n. 格言,谚语;箴言
weasel /ˈwiːzl/ n. 鼬,黄鼠狼;(非正式)狡猾的人;v. 逃避,逃脱;欺骗
perennial /pəˈreniəl/ adj. 多年生的;常年的;四季不断的;常在的;反复的;n. 多年生植物
fuss /fʌs/ n. 大惊小怪,紧张不安;(为小事)大发牢骚;反对,抗议;繁琐的手续,麻烦;v. 大惊小怪,瞎忙活;过分体贴(fuss over);使烦恼,烦扰
enormous /ɪˈnɔːrməs/ adj. 巨大的,极大的;<古>凶暴的,极恶的
lull /lʌl/ v. 使安静,使昏昏欲睡;使(人)放松警惕,哄骗;(使)减弱,平息,停止;n. 间歇,暂时平静;低谷期
admonition /ˌædməˈnɪʃ(ə)n/ n. 警告
elixir /ɪˈlɪksər/ n. 灵丹妙药;炼金药;长生不老药;酏剂
precarious /prɪˈkeriəs/ adj. 摇摇欲坠的,不稳固的;(局势)不确定的,危险的
uninitiated /ˌʌnɪˈnɪʃieɪtɪd/ adj. 不知情的;缺少经验的
blissfully /ˈblɪsfəli/ adv. 幸福地;充满喜悦地
hinge /ˈhɪndʒ/ n. 铰链,合叶;枢纽,关键;铰合部;v. 给(某物)装铰链
insulate /ˈɪnsəleɪt/ v. 使隔热,使隔音,使绝缘;使隔离,使免受(不良影响等);<古>使(陆地)成岛屿
wordy /ˈwɜːrdi/ adj. 冗长的;口头的;唠叨的;文字的
crux /krʌks/ n. 关键,症结;难题;十字架形,坩埚
ironclad /ˈaɪənklæd/ adj. 装甲的;打不破的;坚固的;n. 装甲舰
audible /ˈɔːdəb(ə)l/ adj. 听得见的
Usages & Sentences
Usage of contrast
Contrast that with what happens in the
auto-ized declaration for …
Usage of see the light of day
This is hardly the most encapsulated design that’s seen the light of day
Usage of it is anything but
Revising the code to use
const_iterators should be trivial, but in C++98, it was anything but.This grisly ending is anything but sentimental
Usage of tidy up
In C++11, it’s eminently practical, and C++14 tidies up the few bits of unfinished business that C++11 left behind.
Usage of temper
I must temper your enthusiasm.
Usage of take for granted
for now I’ll just say that you can’t assume that the results of
constexprfunctions areconst, nor can you take for granted that their values are known during compilation.
Usage of remark(提到,说起过)
I remarked earlier that auto variables can also be universal references.
Usage of ’til-death-do-us-part (至死不渝)
The ownership contract between a resource and the
std::shared_ptrs that point to it is of the ’til-death-do-us-part variety.
Usage of afoul of(碰撞,同某物撞在一起;和某人发生冲突)
Repeating types runs afoul of a key tenet of software engineering
Usage of crop up(突然出现)
But they do crop up from time to time
Usage of rest easy(高枕无忧;大放宽心)
You’d rest easy knowing you’d never pay for a copy.
Usage of topple into a pit(掉入陷阱)
An easy way to topple into this pit is to write a perfect forwarding constructor.
Usage of meet the eye(呈现在眼前;显而易见)
The problem here is much worse, however, because there’s more overloading present in
Personthan meets the eye.
Usage of unscramble an egg(Some things can’t be undone. Broken egg shells can’t be put back together.)
It’s a common saying that you can’t unscramble an egg. You break an egg into a bowl, break the yolk membrane with your fork, mix the yolk thoroughly with the white, and stir it around in a hot skillet. The cooking uncurls the egg proteins, breaking some chemical bonds and causing new ones to form.
Now we’ve got a scrambled egg. The egg proteins won’t go back to their raw configuration when they cool, and even if they did it’s impossible to wield the fork in such a way as to separate the yolk from the white. Roomfuls of the latest and greatest laboratory equipment, the best Google algorithms, or even all the king’s horses and all the king’s men would not unscramble our egg. The mixing and cooking are irreversible processes.
Usage of ease into, off-putting
The way to express that idea isn’t particularly difficult, but the syntax is off-putting, especially if you’ve never seen it before, so I’ll ease you into it.
Usage of count your blessings(知足吧;多往好处想;知足常乐)
If you’ve never seen anything like this before, count your blessings.
Usage of flap about(摆动,拍翅飞行)
There’s still one loose end from Item 26 that continues to flap about.
Usage of pull off(赢得;脱下;努力实现)
Move semantics can really pull that off
Usage of keep expectations grounded(符合实际)
The purpose of this Item is to keep your expectations grounded.
Usage of go off(*v.*爆炸;(警报器)响;(电器设备)停止运转;失去兴趣;(食物或饮料)变质;进展;入睡)
We’ve determined we’ll want an alarm that will go off an hour after it’s set and that will stay on for 30 seconds.
Usage of do you good(To have a positive effect on someone)
The existence move support in your compilers is likely to do you little good.
Usage of tear sth. open
tear the box open
Usage of fall into place(依序排列;逐渐被理解)
You may need to consult your favorite C++11 reference before all the details of the foregoing discussion fall into place.
Usage of in the know(知情的;消息灵通的)
But even readers in the know have to mentally map from the number in that placeholder to its position
本末倒置的短语(习语)
put the cart before the horse 前后颠倒
the tail wagging the dog 尾巴摇狗,本末倒置
see the forest for the trees 只见树木不见森林
Twisting a function’s implementation to permit a
noexceptdeclaration is the tail wagging the dog. Is putting the cart before the horse. Is not seeing the forest for the trees. Is…choose your favorite metaphor
in and of itself 就其本身而言(without considering anything else)
if at all possible 如果可能的话
get away 离开;逃脱;出发
cut through 穿过;刺穿;抄近路走过
a的b次方:a to the b;b-th power of a
**in accord with ** 同……相符合;与……一致
conjure up 想起,使在脑海中显现;用魔法召唤
Error-prone pronunciation
declare 的读音是 /dɪˈkler/,e发音是***/i/***。
但是declaration 的读音是 /ˌdekləˈreɪʃn/,并不是*/ˌdikləˈreɪʃn/。即e发音是**/e/,而不是/i/***。
swap 的读音是*/swɑːp/,即a的读音是**/ɑː/***。
clause /klɔːz/
compilation /ˌkɑːmpɪˈleɪʃn/
polynomial /ˌpɒliˈnəʊmiəl/
atomic /əˈtɒmɪk/
epsilon /ˈepsɪlɑːn/
Things to Remember
non-
const引用不能绑定到bit field上A non-
constreference shall not be bound to a bit-field.编译器生成的special member function都是
inline对于
static const的integral类型的类的静态成员变量,可以只声明不定义,编译器会帮忙处理(是把所有用到的地方做替换,而不是帮忙补上定义)。但如果要使用到指向它的指针的时候(需要取得存储地址),那么就会在链接的阶段失败,因为没有定义!
当然有些编译器对这种情况做了支持,即在没有定义的情况下也可以取得其地址(编译器帮了忙)
As a general rule, there’s no need to define integral
staticconstdata members in classes; declarations alone suffice. That’s because compilers performconstpropagation on such members’ values, thus eliminating the need to set aside memory for them.If that value’s address were to be taken (e.g., if somebody created a pointer to it), then that variable would require storage (so that the pointer had something to point to), and the code above, though it would compile, would fail at link-time until a definition for that variable was provided.
lambda expression的本质实际上是:用一种简便的办法,让编译器创建一个类,并创建一个类的对象。
当
std::forward<T>的模板参数T当
T是非引用类型或右值引用的时候,返回的都是右值引用。当
T是左值引用时,返回的是左值引用
Introduction
A useful heuristic to determine whether an expression is an lvalue is to ask if you can take its address. If you can, it typically is. If you can’t, it’s usually an rvalue.
rhs = right hand side
lhs = left hand side
move operations = move constructors, move assignment
copy operations = copy constructors, copy assignment
“…” –> narrow ellipsis
“…” –> wide ellipsis
variadic template
本书认为,argument 叫作形参,而parameter 叫作实参。
In a function call, the expressions passed at the call site are the function’s arguments. The arguments are used to initialize the function’s parameters.
所以形参 (argument)永远是lvalue,而实参(parameter )可能是lvalue,也可能是rvalue。
The distinction between arguments and parameters is important, because parameters are lvalues, but the arguments with which they are initialized may be rvalues or lvalues.
本书中提到的function object,指的是重载了函数operator()的class。也可以直接叫这类object是callable objects。
lambda是一个闭包(closure)
Function objects created through lambda expressions are known as closures
declaration 和 definition 的区别
Declarations introduce names and types without giving details, such as where storage is located or how things are implemented.
Definitions provide the storage locations or implementation details
Function signature
本书提到的function signature,指的是函数返回值加上函数参数的类型,而函数名称和参数的名称并不是function signature的一部分。
I define a function’s signature to be the part of its declaration that specifies parameter and return types. Function and parameter names are not part of the signature. In the example above, func’s signature is bool(const Widget&).
backport的痛苦 的描述方式
Not only can they lead to future porting headaches
C++标准委员会提到的Undefined Behavior(UB),指的是它们的行为不可预测。
Sometimes a Standard says that the result of an operation is undefined behavior. That means that runtime behavior is unpredictable.
常见的Undefined Behavior
使用
[]对std::vector的越界访问对未初始化的迭代器的解引用(dereferencing an uninitialized iterator)
发生数据竞争(engaging in a data race,即多个线程写同一块内存地址的数据)
Chapter 1 Deducing Types
类型推导(type deduction)可能出现的地方
In calls to function templates
In most situations where
autoappearsIn
decltypeexpressions, and, as of C++14, where the enigmaticdecltype(auto)construct is employed.
本章的主要内容
It explains how template type deduction works, how auto builds on that, and how decltype goes its own way. It even explains how you can force compilers to make the results of their type deductions visible, thus enabling you to ensure that compilers are deducing the types you want them to.
类型推导如何工作(起作用)
auto如何工作decltype如何起作用如何强制编译器显式告知类型推导的结果
Item 1: Understand template type deduction
一个(通用的)模板函数f的声明(定义),这里ParamType表示函数形参param的类型名称
template<typename T>
void f(ParamType param); // A template function declarition
调用f,这里expr表示调用时的表达式(值)
f(expr); // call f with some expression
// compilers deduce T and ParamType from expr
在调用函数f时,编译器会通过expr来推导两个类型,T和ParamType。虽然有很多情况这两种类型最终是相同的,但也有很多情况下这两种类型是不同的。
推导类型T,不仅取决于expr表达式的类型,也取决于形参的类型ParamType。
The type deduced for
Tis dependent not just on the type ofexpr, but also on the form ofParamType
事实上,情况分为三种:
ParamType是一个指针或引用,但不是万能引用ParamTypeis a pointer or reference type, but not a universal reference.ParamType是一个万能引用ParamTypeis a universal reference.ParamType既不是指针也不是引用(包括万能引用)。ParamTypeis neither a pointer nor a reference.
第一种情况
ParamType是一个指针或引用,但不是万能引用
这种情况下,对于类型T的推导原则如下。(是的!我们实际上当然是在推导类型T,而不是ParamType!,因为类型T推导出来之后,ParamType也就确定了,因为ParamType实际上这里指的是T带一个修饰关键字的变种类型,比如const T&)
首先忽略
ParamType的引用部分(即&)如果
expr是一个引用,也忽略它的引用部分(即&)按照模式匹配的办法,匹配
expr和ParamType,并以此决定类型T!
ParamType - T&
如果ParamType是非const的引用类型,f函数如下,
template<typename T>
void f(T ¶m); // param is a reference
定义了一些变量,并且以其为表达式调用函数f,那么编译器就会推断出类型T如下
int x = 27; // x is an int
const int cx = x; // cx is a const int
const int &rx = x; // rx is a reference to x as a const int
f(x); // T is int, param's type is int&
f(cx); // T is const int, param's type is const int&
f(rx); // T is const int, param's type is const int&
调用函数
f(x),按照上述规则,推导过程如下忽略
ParamType的引用部分,得到T此时
x不是引用,所以略过第二条规则直接用
int和T匹配,推导出T就是int(同时也推导出ParamType就是T&)
调用函数
f(cx),按照上述规则,推导过程如下忽略
ParamType的引用部分,得到T此时
cx不是引用,所以略过第二条规则直接用
const int和T匹配,推导出T就是const int(同时也推导出ParamType就是const int&)
调用函数
f(rx),按照上述规则,推导过程如下忽略
ParamType的引用部分,得到T此时
rx是引用,所以忽略它的引用部分得到const int。直接用
const int和T匹配,推导出T就是const int(同时也推导出ParamType就是const intT&)
ParamType - const T&
如果ParamType是const的引用类型,f函数如下
template<typename T>
void f(const T ¶m); // param is a reference
同样地有如下变量定义,和函数调用,那么编译器就会推断出类型T如下
int x = 27; // x is an int
const int cx = x; // cx is a const int
const int &rx = x; // rx is a reference to x as a const int
f(x); // T is int, param's type is const int&
f(cx); // T is int, param's type is const int&
f(rx); // T is int, param's type is const int&
这种情况下,稍有区别的是,因为已经假定了param的类型是const了,所以对于类型T的推导就不用再考虑const修饰符了。
调用函数
f(x),按照上述规则,推导过程如下忽略
ParamType的引用部分(以及const修饰符),得到T。此时
x不是引用,所以略过第二条规则直接用
int和T匹配,推导出T就是int(同时也推导出ParamType就是T&)
调用函数
f(cx),按照上述规则,推导过程如下忽略
ParamType的引用部分(以及const修饰符),得到T。此时
cx不是引用,所以略过第二条规则。但同时忽略cx的const,得到int直接用
int和T匹配,推导出T就是int(同时也推导出ParamType就是const int&)
调用函数
f(rx),按照上述规则,推导过程如下忽略
ParamType的引用部分(以及const修饰符),得到T。此时
rx是引用,所以忽略它的引用部分,同时也忽略const,得到int。直接用
int和T匹配,推导出T就是int(同时也推导出ParamType就是const intT&)
ParamType - T*
如果ParamType是非const的指针类型,f函数如下
template<typename T>
void f(T *param); // param is a pointer
有如下变量定义,和函数调用,那么编译器就会推断出类型T如下
int x = 27; // x is an int
const int *px = &x; // px is a pointer to const int
f(&x); // T is int, param's type is int*
f(px); // T is const int, param's type is const int*
调用函数
f(&x),按照上述规则,推导过程如下忽略
ParamType的指针部分,得到T此时
x不是指针,所以略过第二条规则直接用
int和T匹配,推导出T就是int(同时也推导出ParamType就是int*)
调用函数
f(px),按照上述规则,推导过程如下忽略
ParamType的指针部分,得到T此时
px是指针,所以忽略它的引用部分得到const int。直接用
const int和T匹配,推导出T就是const int(同时也推导出ParamType就是const int*)
ParamType - const T*
如果ParamType是const的指针类型,f函数如下
template<typename T>
void f(const T *param); // param is a pointer
有如下变量定义,和函数调用,那么编译器就会推断出类型T如下
int x = 27; // x is an int
const int *px = &x; // px is a pointer to const int
f(&x); // T is int, param's type is const int*
f(px); // T is int, param's type is const int*
同样的,这种情况下,因为已经假定了param的类型是const了,所以对于类型T的推导就不用再考虑const修饰符了。
调用函数
f(&x),按照上述规则,推导过程如下忽略
ParamType的指针部分(以及const修饰符),得到T此时
x不是指针,所以略过第二条规则直接用
int和T匹配,推导出T就是int(同时也推导出ParamType就是const int*)
调用函数
f(px),按照上述规则,推导过程如下忽略
ParamType的指针部分(以及const修饰符),得到T此时
px是指针,所以忽略它的引用部分,同时也忽略const,得到int。直接用
int和T匹配,推导出T就是int(同时也推导出ParamType就是const int*)
第二种情况
ParamType是一个万能引用
ParamType - T&&
这种情况有些特殊,对于类型T的推导原则如下。
如果
expr是一个左值,那么T和ParamType都会被推导为左值引用这是在模板类型推导中,
T会被推导为引用的唯一一种情况尽管
ParamType使用了像右值引用一样的声明语法,但它最终却推导成了左值引用。
如果
expr是一个右值,那么就按照前面提到的第一种情况进行推导首先忽略
ParamType的引用部分(即&&)如果
expr是一个引用,也忽略它的引用部分(即&&)按照模式匹配的办法,匹配
expr和ParamType,并以此决定类型T
这种情况下,函数f如下
template<typename T>
void f(T &¶m); // param is now a universal reference
定义了一些变量,并且以其为表达式调用函数f,那么编译器就会推断出类型T如下
int x = 27; // x is an int
const int cx = x; // cx is a const int
const int &rx = x; // rx is a reference to x as a const int
f(x); // x is lvalue, so T is int&, param's type is also int&
f(cx); // cx is lvalue, so T is const int&, param's type is also const int&
f(rx); // rx is lvalue, so T is const int&, param's type is also const int&
f(27); // 27 is rvalue, so T is int, param's type is therefore int&&
调用函数
f(x)x是一个左值(因为是具名变量),所以T被推导为int &,同时ParamType也被推导为int &
调用函数
f(cx)cx是一个左值(因为是具名变量),所以T被推导为const int &,同时ParamType也被推导为const int &
调用函数
f(rx)rx是一个左值引用,但同样的,因为是具名变量,所以它也是左值,所以T被推导为const int &,同时ParamType也被推导为const int &
调用函数
f(27)27是一个右值,所以按照前面提到的第一种情况推导首先忽略
T&&的引用部分,得到T其次
27是右值,但不是引用(而是int)直接用
int和T匹配,得到T就是int,所以得到ParamType就是int &&
第三种情况
ParamType既不是指针,也不是任何一种引用
ParamType - T
这种情况下,处理的是值传递(pass-by-value),那么param就是一个传入值的拷贝(新对象)。
推导规则如下,
如果
expr是一个引用,忽略它的引用部分如果
expr同时还是const或volatile,忽略它的const或volatile部分
这种情况下,函数f如下
template<typename T>
void f(T param); // param is now passed by value
定义了一些变量,并且以其为表达式调用函数f,那么编译器就会推断出类型T如下
int x = 27; // as before
const int cx = x; // as before
const int& rx = x; // as before
const char* const p = "Fun with pointers" // ptr is const pointer to const object
f(x); // T's and param's types are both int
f(cx); // T's and param's types are again both int
f(rx); // T's and param's types are still both int
f(p); // T's and param's types are const int*
调用函数
f(x)x不是引用x既也不是const,也不是volatile因此直接用
x的类型int和T做匹配,所以推导出T就是int,因此param的类型也是int(非const)
调用函数
f(cx)x不是引用x是const,但不是volatile,所以只用忽略const因此直接
int和T做匹配,所以推导出T就是int,因此param的类型也是int(非const)
调用函数
f(rx)x是引用,所以忽略它的引用部分x是const,但不是volatile,所以只用忽略const因此直接
int和T做匹配,所以推导出T就是int,因此param的类型也是int(非const)
调用函数
f(p)x不是引用x是const,这个const指的是这个pointer不能指向其他的内存地址,即这个pointer本身是const,所以忽略它(因为值传递就是拷贝)。不是volatile所以不管volatile。因此直接
const char*和T做匹配,所以推导出T就是const char*,因此param的类型也是const char*,即指针是指向一个内容不可以被修改的地址,但这个指针本身是可以指向其它内存地址的。
如果实参是数组
定义数组变量
const char name[] = "J. P. Briggs"; // name's type is const char[13]
const char * ptrToName = name; // array decays to pointer
首先,在C中,如果用一个数组去初始化一个指针,那么指针就指向数组的第一个元素,这叫作array decays。
这个array-to-pointer decay rule,和这里讨论的类型推导无关,是C的特性。
类似的,如果函数的参数是一个数组,那么实际上下面两种函数声明是等价的
void myFunc(int param[]);
void myFunc(int* param); // same function as above
这实际上表明,指针和数组实际上是等价的。
函数模板f声明如下,调用函数并传入数组作为参数
template<typename T>
void f(T param); // template with by-value parameter
f(name); // what types are deduced for T and param?
此时,T被推导为const char*。这是由于传入的数组,被等价地认为是一个指针,然后再进行类型推导。
函数模板f声明如下,调用函数并传入数组作为参数
template<typename T>
void f(T ¶m); // template with by-value parameter
f(name); // what types are deduced for T and param?
由于声明了引用&的缘故,此时,T被推导为const char [13],而不再推导为指针了,同时ParamType变为const char (&)[13]。
利用这种特性,可以通过声明成T&,在编译期间计算得到一个数组的长度。
// Return size of an array as a compile-time constant. (The
// array parameter has no name, because we care only about
// the number of elements it contains.)
template<typename T, std::size_t N>
constexpr std::size_t arraySize(T (&)[N]) noexcept {
return N;
}
使用举例
int keyVals[] = { 1, 3, 7, 9, 11, 22, 35 }; // keyVals has 7 elements
int mappedVals[arraySize(keyVals)]; // so does mappedVals
std::array<int, arraySize(keyVals)> mappedVals; // mappedVals' size is 7
如果实参是函数
同样地,如果是函数作为参数,也会和数组的array-to-pointer decay rule一样,函数会退化为函数指针。
void someFunc(int, double); // someFunc is a function; type is void(int, double)
template<typename T>
void f1(T param); // in f1, param passed by value
template<typename T>
void f2(T ¶m); // in f2, param passed by ref
f1(someFunc); // param deduced as ptr-to-func; type is void (*)(int, double)
f2(someFunc); // param deduced as ref-to-func; type is void (&)(int, double)
f1声明的是值传递,如果函数作为参数传入,会推导出来类型T是函数指针:void (*)(int, double)
f2声明的是引用传递,如果函数作为参数传入,会推导出来类型T是函数引用:void (&)(int, double)
Things To Remember
Things to Remember
During template type deduction, arguments that are references are treated as non-references, i.e., their reference-ness is ignored.
When deducing types for universal reference parameters, lvalue arguments get special treatment.
When deducing types for by-value parameters,
constand/orvolatilearguments are treated as non-constand non-volatile.During template type deduction, arguments that are array or function names decay to pointers, unless they’re used to initialize references.
Item 2: Understand auto type deduction
auto 类型推导就是template 类型推导(有一个例外)
autotype deduction is template type deduction.There’s a direct mapping between
templatetype deduction andautotype deduction.Deducing types for auto is, with only one exception, the same as deducing types for templates.
在Item 1中,(通用的)函数模板和对应的调用分别如下
template<typename T>
void f(ParamType param); // A template function declarition
f(expr); // call f with some expression
// compilers deduce T and ParamType from expr
而编译器负责推导类型T以及类型ParamType。
对应于auto的类型推导,auto扮演了T的角色,而对应变量的type specifier扮演了ParamType的角色,例如
auto x = 27; // auto is T, type specifier is auto (ParamType is auto)
const auto cx = x; // auto is T, type specifier is const auto (ParamType is const auto)
const auto& rx = x;// auto is T, type specifier is const auto& (ParamType is const auto&)
为了推导类型,编译器就好像假设存在以下对应的template函数(和相应的函数调用)一样
template<typename T> // conceptual template for
void func_for_x(T param); // deducing x's type
func_for_x(27); // conceptual call: param's
// deduced type is x's type
template<typename T> // conceptual template for
void func_for_cx(const T param); // deducing cx's type
func_for_cx(x); // conceptual call: param's
// deduced type is cx's type
template<typename T> // conceptual template for
void func_for_rx(const T& param); // deducing rx's type
func_for_rx(x); // conceptual call: param's
// deduced type is rx's type
auto类型推导的情况
在Item1中,对template函数,根据ParamType把推导类型的情况分成了三种。
类似的,对于auto 可以根据 type specifier 把情况也分成三种。
type specifier 是一个指针或引用,但不是万能引用
type specifier 是万能引用
type specifier 既不是指针也不是任何一种引用
Case 1: The type specifier is a pointer or reference, but not a universal reference.
Case 2: The type specifier is a universal reference.
Case 3: The type specifier is neither a pointer nor a reference.
As you can see, auto type deduction works like template type deduction. They’re essentially two sides of the same coin.
三种情况对应的例子
// Case 1: A reference/pointer, but not a universal reference
const auto& rx = x;
// Case 2: A universal reference
auto&& uref1 = x; // x is int and lvalue, so uref1's type is int&
auto&& uref2 = cx; // cx is const int and lvalue, so uref2's type is const int&
auto&& uref3 = 27; // 27 is int and rvalue, so uref3's type is int&&
// Case 3: Neither a pointer nor a reference of any kind
auto x = 27;
const auto cx = x;
和Item1中相对应的,如果是数组或者函数的时候,会发生同样的 array-to-pointer decay和function-to-pointer decay rule。
const char name[] = "R. N. Briggs"; // name's type is const char[13]
auto arr1 = name; // arr1's type is const char*
auto& arr2 = name; // arr2's type is const char (&)[13]
void someFunc(int, double); // someFunc is a function; type is void(int, double)
auto func1 = someFunc; // func1's type is void (*)(int, double)
auto& func2 = someFunc; // func2's type is void (&)(int, double)
auto推导和template推导唯一的不同
auto的几种初始化情况
例如,可以如下定义一个int值,虽然形式不同,但值都是一样的:int。
int x1 = 27; // C++98
int x2(27); // C++98
int x3 = { 27 }; // C++11
int x4{ 27 }; // C++11
如果使用auto关键字替换上面的int,得到下面的定义(可以编译通过)
auto x1 = 27; // type is int, value is 27
auto x2(27); // ditto
auto x3 = { 27 }; // type is std::initializer_list<int>, value is { 27 }
auto x4{ 27 }; // type is int, in win7, MSYS2, g++ version 12.1.0
但前面两个(x1,x2)的类型被推导为int,而后面的(x3)被推断为std::initializer_list<int>,其值是{27}。而最后的x4,实际上也被推导为int,而并不是std::initializer_list<int>。
注意,经过验证,发现x4实际上也被推导为int,而并不是std::initializer_list<int>。环境是win7, MSYS2, g++ version 12.1.0。
需要注意的两点
如果在花括号里面的值不是同一种类型的话,会编译失败
auto x5 = { 1, 2, 3.0 }; // error! can't deduce T for std::initializer_list<T>
对于上面的
x3,x4和x5,它们同时发生了两种类型推导因为使用了花括号(braces),所以它们必须被推导为
std::initializer_list因为
std::initializer_list<T>是类模板,所以类型T也必须要被推导
唯一的不同
简单来说,唯一的区别是:
如果使用列表初始化,auto会推导为std::initializer_list<TypeName>类型,而template的推导却不能推断出来std::initializer_list<TypeName>类型。
The treatment of braced initializers is the only way in which auto type deduction and template type deduction differ.
(这里的TypeName是指某个确定的类型名)
换句话说,使用同一个列表(braced initializer),去初始化一个使用auto声明的变量,会推断为一个std::initializer_list,但是用同样的这个列表,传递给一个模板函数,推断会失败。
So the only real difference between auto and template type deduction is that auto assumes that a braced initializer represents a std::initializer_list, but template type deduction doesn’t.
auto x = { 11, 23, 9 }; // x's type is std::initializer_list<int>
template<typename T> // template with parameter
void f(T param); // declaration equivalent to x's declaration
f({ 11, 23, 9 }); // error! can't deduce type for T
上面的例子中,使用用一个列表{ 11, 23, 9 },auto推断出来了std::initializer_list<int>,而T却推断失败了。
如果想要使T推断成功,需要把ParamType声明称为如下的形式
template<typename T>
void f(std::initializer_list<T> initList);
f({ 11, 23, 9 }); // T deduced as int, and initList's type is std::initializer_list<int>
auto 在C++14 中的特点
在C++14中,
允许声明函数的返回值是
auto,并进行类型推导允许lambda中形参声明为
auto,并进行类型推导
但上面提到的两种语法,使用的是模板类型推导(template type deduction),而不是auto类型推导。
也就是说,如果传递一个列表,上面两种情况下,auto进行类型推导会失败。
// C++14, return type is auto which is permitted
auto createInitList() {
return { 1, 2, 3 }; // error!! can't deduce type
} // for { 1, 2, 3 }
// C++14, lambda's paramter can be auto
std::vector<int> v;
auto resetV = &v](const auto& newValue) { v = newValue; }; // C++14
resetV({ 1, 2, 3 }); // error!! can't deduce type
// for { 1, 2, 3 }
Things to Remember
autotype deduction is usually the same as template type deduction, butautotype deduction assumes that a braced initializer represents astd::initializer_list, and template type deduction doesn’t.
autoin a function return type or a lambda parameter implies template type deduction, notauto typededuction.
Item 3: Understand decltype
关键字decltype可以告知我们一个名字或者一个表达式的类型。
decltype 用法示例
decltype的一些例子
const int i = 0; // decltype(i) is const int
bool f(const Widget &w); // decltype(w) is const Widget&
// decltype(f) is bool(const Widget&)
struct Point {
int x, y; // decltype(Point::x) is int
}; // decltype(Point::y) is int
Widget w; // decltype(w) is Widget
if (f(w)) {} // decltype(f(w)) is bool
template<typename T> // simplified version of std::vector
class vector {
public:
// ...
T& operator[](std::size_t index);
// ...
};
vector<int> v; // decltype(v) is vector<int>
if (v[0] == 0) // decltype(v[0]) is int&
Trailing Return Type优点
decltyp在C++11中最主要的用法,也许是当函数返回值的类型取决于其参数时,声明它(一个函数返回值)的类型
In C++11, perhaps the primary use for
decltypeis declaring function templates where the function’s return type depends on its parameter types.
比如下面的例子,返回值是输入参数的[]操作返回值,那么就可以使用所谓的Trailing Return Type来声明其返回值的类型。
template<typename Container, typename Index>
auto authAndAccess(Container &c, Index i) -> decltype(c[i]) {
authenticateUser();
return c[i];
}
在使用Trailing Return Type来声明函数的返回值的时候,函数名前面的auto和类型推导无关,这个auto只是用来说明C++11的Trailing Return Type被用来声明函数返回值类型。
trailing return type的优点
C++11中就可以使用
优点是因为类型后置了,所以函数参数可以在类型中使用
Rather, it indicates that C++11’s trailing return type syntax is being used, i.e., that the function’s return type will be declared following the parameter list (after the “->”). A trailing return type has the advantage that the function’s parameters can be used in the specification of the return type.
使用decltype的潜在陷阱
陷阱在函数返回值推导
在C++11中可以使用Trailing Return Type来利用decltype声明返回值类型
template<typename Container, typename Index>
auto authAndAccess(Container &c, Index i) -> decltype(c[i]) {
authenticateUser();
return c[i];
}
可以使用上面的定义来修改容器中的元素
std::vector<int> ivec{0, 1, 2, 3, 4, 5};
authAndAccess(ivec, 0) = 100;
在C++14中,支持省略Trailing Return Type,而直接由auto来推导函数返回值类型
template<typename Container, typename Index>
auto authAndAccess(Container &c, Index i) {
authenticateUser();
return c[i];
}
但此时如果使用上述函数定义,那么如下的使用就会编译失败
std::vector<int> ivec{0, 1, 2, 3, 4, 5};
authAndAccess(ivec, 0) = 100; // fail to compile if use the definition above
原因是,在C++14中,auto在作为函数返回值进行类型推导时,遵循的依据和进行template类型推导时的相同,即如果返回值中带有引用(reference-ness,&),那么这个引用就会被忽略,然后进行推导。
这就导致上面的函数实际上推导出来的是,返回一个新的对象,而它是一个rvalue,那么给一个右值赋值,就会产生编译错误。
为了避免这个问题,在C++14中,可以使用decltype(auto)来解决。这里
auto是声明这里的类型需要被推导decltype是说明在推导的过程中,采用的是decltype的rule
autospecifies that the type is to be deduced, anddecltypesays thatdecltyperules should be used during the deduction.
template<typename Container, typename Index>
decltype(auto) authAndAccess(Container &c, Index i) {
authenticateUser();
return c[i];
}
上面几个函数中的 c 都是左值引用,所以必须绑定到左值上。
为了能够绑定到右值,可以使用万能引用,而且为了保留返回值的引用特性(reference-ness),需要使用完美转发(perfect forwarding:std::forward)
// Need C++14 support
template<typename Container, typename Index>
decltype(auto) authAndAccess(Container &&c, Index i) {
authenticateUser();
return std::forward<Container>(c)[i];
}
// C++11 support is enough
template<typename Container, typename Index>
auto authAndAccess(Container &&c, Index i) -> decltype(std::forward<Container>(c)[i]) {
authenticateUser();
return std::forward<Container>(c)[i];
}
// get_temp_vec() returns an rvalue
auto val0 = authAndAccess(get_temp_vec(), 1);
此外,decltype(auto)还可以用在其它地方
Widget w;
const Widget& cw = w;
auto myWidget1 = cw; // auto type deduction: myWidget1's type is Widget
decltype(auto) myWidget2 = cw; // decltype type deduction:
// myWidget2's type is const Widget&
陷阱在左值表达式
if an
lvalueexpression other than a name has typeT,decltypereports that type asT&.
使用decltype(x)和decltype((x)),得到的类型是不同的
int x = 0; // decltype(x) is int
// decltype((x)) is int&
这样的情况在C++14中的函数返回值为auto的时候,需要特别注意。
在下面的f2中,实际上的返回值是int&类型,所以它实际上返回了一个local variable的引用,这实际上是应该避免的。
decltype(auto) f1() {
int x = 0;
return x; // decltype(x) is int, so f1 returns int
}
decltype(auto) f2() {
int x = 0;
return (x); // decltype((x)) is int&, so f2 returns int&
}
Things to Remember
decltypealmost always yields the type of a variable or expression without any modifications.For lvalue expressions of type T other than names,
decltypealways reports a type ofT&.C++14 supports
decltype(auto), which, like auto, deduces a type from its initializer, but it performs the type deduction using thedecltyperules.
Item 4: Know how to view deduced types
本节中指出,可以使用boost::type_index中的类来获取类型的名称,并且可以使用对应的函数获得可读性较强的名称字符串。
头文件:
boost/type_index.hpp类:
boost::typeindex::type_id_with_cvr<T>函数:
boost::typeindex::type_id_with_cvr<T>().pretty_name()
#include <boost/type_index.hpp>
template<typename T>
void f(const T& param) {
using std::cout;
using boost::typeindex::type_id_with_cvr;
// show T
cout << "T = "
<< type_id_with_cvr<T>().pretty_name()
<< '\n';
// show param's type
cout << "param = "
<< type_id_with_cvr<decltype(param)>().pretty_name()
<< '\n';
}
Chapter 2 auto
Item 5: Prefer auto to explicit type declarations
The type of a closure is known only to the compiler, hence can’t be written out.
auto的优点
避免未初始化的值(
auto定义变量必须初始化)
int x1; // potentially uninitialized
auto x2; // error! initializer required
auto x3 = 0; // fine, x's value is well-defined
可以表示只有编译器才知道的类型(闭包closure)
lambda可以包含一个闭包
std::function也可以包含一个闭包
auto derefUPLess = // comparison func.
[](const std::unique_ptr<Widget>& p1, // for Widgets
const std::unique_ptr<Widget>& p2) // pointed to by
{ return *p1 < *p2; }; // std::unique_ptrs
// Need C++14 support
auto derefLess = // C++14 comparison
[](const auto& p1, const auto& p2) // function for values pointed
{ return *p1 < *p2; }; // to by anything pointer-like
What’s a
std::functionobject?
std::functionis a template in the C++11 Standard Library that generalizes the idea of a function pointer. Whereas function pointers can point only to functions, however,std::functionobjects can refer to any callable object, i.e., to anything that can be invoked like a function.Just as you must specify the type of function to point to when you create a function pointer (i.e., the signature of the functions you want to point to), you must specify the type of function to refer to when you create a
std::functionobject.
std::function对象是什么?
std::function是C++11标准库中的一个模板(类),目的是使函数指针的思想通用化std::function对象可以引用任何可调用(callable)的对象,而函数指针只能指向函数std::function对象的初始化,是通过指明模板参数,即函数的signature来实现的(与创建函数指针类似)
auto和std::function包含闭包时的差异
除了语法的详细程度、以及需要重复参数的类型名称,std::function和auto实际上是有一些差别的。
简单来说就是std::function比auto包含闭包时,要占用更多内存,而且调用运行比较慢。
使用
auto声明的变量,它的类型和它所包含的的闭包类型一致。它所占用的内存空间大小,实际上就是它所包含的闭包占用的内存空间大小。使用
std::function声明的变量,它实际上是std::function这个template类的一个实例,这个实例包含了一个闭包。所以std::function对于任意一个函数signature,它所占用的内存大小是固定的。这样导致的问题是它所包含的闭包也许要使用更多的内存空间,此时std::function就要在堆上申请更多的内存来存储这个闭包。由于实现的细节和内联的限制,通过std::function来调用一个闭包,几乎必然比通过调用auto声明的对象要慢,而且占用更多内存(还有out-of-memory的exception)。
An
auto-declared variable holding a closure has the same type as the closure, and as such it uses only as much memory as the closure requires. The type of astd::function-declared variable holding a closure is an instantiation of thestd::functiontemplate, and that has a fixed size for any given signature. This size may not be adequate for the closure it’s asked to store, and when that’s the case, the std::function constructor will allocate heap memory to store the closure.
Advantages of auto
avoidance of uninitialized variables
verbose variable declarations
the ability to directly hold closures
ability to avoid “type shortcuts” (says by Scott Meyers)
std::unordered_map的迭代器的返回值
std::unordered_map中,key的部分实际上是const。
即std::unordered_map中存储的元素,在插入map之后,如果再次从map中取得(访问),得到的类型实际上是std::pair<const KeyType, ValueType>,这里的KeyType和ValueType分别是key的类型和value的类型。
所以,如果是在使用auto声明的for循环中,编译器可以帮助避免这个临时变量的问题。
Item 6: Use the explicitly typed initializer idiom when auto deduces undesired types
auto with proxy classes : operator [] in std::vector<bool>
一般地,std::vector<T>::operator[]都会返回容器中对应索引元素的引用(即T&),但std::vector<bool>是例外,它的operator[]返回一个新的object,类型是一个class std::vector<bool>::reference,它可以转换为bool类型,或者由bool类型转换而来。
这个class是定义在std::vector<bool>中。
class vector<bool>::reference {
friend class vector;
reference() noexcept; // no public constructor
public:
~reference();
operator bool () const noexcept; // convert to bool
reference& operator= (const bool x) noexcept; // assign from bool
reference& operator= (const reference& x) noexcept; // assign from bit
void flip(); // flip bit value.
};
所以,如果使用类似bool b = bvec[0]的操作,bvec[0]会返回一个std::vector<bool>::reference,然后它被隐式地转换为一个bool,而不是一个bool&。
这个问题产生的原因是,std::vector<bool>是std::vector的一个特化template,它内部使用了bits来存储这些对应的bool值(一个bit对应一个bool),但C++禁止引用bits,所以就不能像正常的std::vector一样,operator[]返回T&,所以引入了这个class,来模拟bool&的行为。
使用static_cast帮助auto进行类型推导
为了防止auto在某些情况下被Proxy Class所诱导而推导出所需的类型,可以使用static_cast来帮助编译器进行正确推导出我们想要的类型。
如书中所述,下面的代码在auto处会被推导称为一个std::vector<bool>::reference。
std::vector<bool> features(const Widget& w);
Widget w;
auto highPriority = features(w)[5]; // is w high priority?
processWidget(w, highPriority); // process w in accord with its priority
这个std::vector<bool>::reference就是一个proxy class,它的行为取决于它的实现。
书中提到了一种可能的实现:使用一个指针指向bits,并加上一个offset,以便找到对应的bit。
在这样的实现下,上面的代码就回产生undefined behavior。
原因是features(w)返回一个临时的std::vector<bool>,进而features(w)[5]返回一个std::vector<bool>::reference,然后再赋值给highPriority并由编译器来推导其类型,而此时临时的std::vector<bool>已经被销毁,这就导致std::vector<bool>::reference中的指针变成了一个dangling pointer,那么就可能会出问题。
解决这个问题的办法,是使用static_cast,它显式地(在编译期间)将起转换成bool(std::vector<bool>::reference提供的bool转换),然后编译器再将highPriority推导为bool类型。
auto highPriority = static_cast<bool>(features(w)[5]);
some classes in C++ libraries employing a technique known as expression templates
As a general rule, “invisible” proxy classes don’t play well with
auto
使用static_cast类显式说明正在做特意的转换
如书中所述,可以使用static_cast,除了帮助转换proxy class以便auto正确推导外,还可以利用它,显式说明当前正在做特意的转换,以便引起注意。
double calcEpsilon(); // return tolerance value
float ep = calcEpsilon(); // impliclitly convert: double → float
auto ep = static_cast<float>(calcEpsilon()); // Use static_cast + auto
Things to Remember
“Invisible” proxy types can cause
autoto deduce the “wrong” type for an initializing expression.The explicitly typed initializer idiom forces
autoto deduce the type you want it to have.
Chapter 3 Moving to Modern C++
C++11和C++14值得大书特书的突出特性
auto
smart pointers
move semantics
lambdas
concurrency
需要解答并掌握背后原因的结果问题
When should you use braces instead of parentheses for object creation?
创建对象时,为什么应该使用花括号(
{})而不是圆括号(())
Why are alias declarations better than
typedefs?为什么
alias声明要比typedef更好?
How does
constexprdiffer fromconst?constexpr和const相比,有何不同?
What’s the relationship between
constmember functions and thread safety?const成员函数和线程安全之间有什么关系?
Item 7: Distinguish between () and {} when creating objects
C++中,初始化对象的语法主要有如下几种
括号(
(),parentheses)等号(
=,equal sign)花括号(
{},curly braces)等号+花括号(
= {},equals-sign-plus-braces)
int x(0); // initializer is in parentheses
int y = 0; // initializer follows "="
int z{ 0 }; // initializer is in braces
int z = { 0 }; // initializer uses "=" and braces
C++中通常把”等号+花括号“(equals-sign-plus-braces)的形式等同于花括号
其中,花括号是由C++11引入的,称为uniform initialization,Scott Meyers更喜欢叫它braced initialization。
braced initialization为何uniform?
几个特点
可以指定一个集合来初始化容器
C++98做不到
可以用来指定类数据成员的默认初始化值
等号
=也可以用于此用途,但圆括号()不行
可以用来初始化uncopyable objects (比如
std::atomic)圆括号
()也可以用于此用途,但等号=不行
由此可见,{}花括号初始化为什么叫做uniform initialization了
std::vector<int> v{ 1, 3, 5 }; // v's initial content is 1, 3, 5
class Widget {
private:
int x{ 0 }; // fine, x's default value is 0
int y = 0; // also fine
int z(0); // error!!!
};
std::atomic<int> ai1{ 0 }; // fine
std::atomic<int> ai2(0); // fine
std::atomic<int> ai3 = 0; // error!!!
关于类的数据成员的默认值
在C++11中,类的成员函数可以使用等号或花括号来设定成员变量的默认值,这可以保证当这些成员没有被构造函数所初始化时,就能有默认值的设定。但如果这些成员在构造函数(默认构造、拷贝构造等等)被初始化了,那么这些在定义成员变量时的默认值就会被覆盖,而使用在构造函数时所初始化的值。
花括号初始化的优点和缺点
优点
防止类型范围缩减转换(narrowing conversions)
防止“最烦人解析”(most vexing parse)
缺点
当存在参数为
std::initializer_list的构造函数时,可能导致非预期的重载构造函数被调用
优缺点的例子
关于第一个优点,实际上是说用一个类型范围较大的值去初始化一个范围类型较小的值,编译会失败
double x = 0, y = 1, z = 2;
int sum1{ x + y + z }; // error! sum of doubles may not be expressible as int
int sum2(x + y + z); // okay (value of expression truncated to an int)
int sum3 = x + y + z; // ditto
第二个优点,实际上是说,在调用默认构造函数(或者调用有默认值的构造函数而没有传参)时,编译器无法区分到底是在调用一个构造函数,还是在声明一个函数(因为看起来没有任何区别)。而使用花括号初始化,就能避免这个问题。
Widget w1(10); // call Widget ctor with argument 10
Widget w2(); // most vexing parse! declares a function
// named w2 that returns a Widget!
Widget w3{}; // calls Widget ctor with no args
关于缺点,当没有参数为std::initializer_list的构造函数时,花括号和圆括号初始化会得到一致的结果
class Widget {
public:
Widget(int i, bool b); // ctors not declaring
Widget(int i, double d); // std::initializer_list params
};
Widget w1(10, true); // calls first ctor
Widget w2{10, true}; // also calls first ctor
Widget w3(10, 5.0); // calls second ctor
Widget w4{10, 5.0}; // also calls second ctor
但是当存在参数为std::initializer_list的构造函数时,只要哪怕存在一种类型转换的可能,花括号和初始化会就会调用参数为std::initializer_list的重载构造函数,但这会导致一些意外情况发生。
这里说的至少一种类型转换的可能,包括narrowing conversion。(尽管花括号初始化禁止narrowing conversion,但编译器确实会这么做,并最终导致编译失败,下面的第三个例子说明了这个问题)
比如下面的第一个例子,花括号初始化时,发现10、true和5都能转换为long double(花括号初始化不允许narrowing conversion,但允许向范围更大的类型转换),那么就会将它们转换为long double,并调用带有参数为std::initializer_list的重载构造函数,但事实上,这两个重载函数调用,并不是最佳的匹配。
class Widget {
public:
Widget(int i, bool b); // ctors not declaring
Widget(int i, double d); // std::initializer_list params
Widget(std::initializer_list<long double> il); // added
};
Widget w1(10, true); // uses parens and, as before, calls first ctor
Widget w2{10, true}; // uses braces, but now calls std::initializer_list ctor
// (10 and true convert to long double)
Widget w3(10, 5.0); // uses parens and, as before, calls second ctor
Widget w4{10, 5.0}; // uses braces, but now calls std::initializer_list ctor
// (10 and 5.0 convert to long double)
下面的第二个例子说明了,甚至连copy-ctor和move-ctor都存在被“劫持”的可能(因为object重载了一个转换为float的运算符,导致编译器发现可以从float向long double发生类型转换,从而调用参数为std::initializer_list的重载构造函数,但这并不是所希望的)
class Widget {
public:
Widget(int i, bool b); // as before
Widget(int i, double d); // as before
Widget(std::initializer_list<long double> il); // as before
operator float() const; // convert to float
};
Widget w5(w4); // uses parens, calls copy ctor
Widget w6{w4}; // uses braces, calls std::initializer_list ctor
// (w4 converts to float, and float converts to long double)
Widget w7(std::move(w4)); // uses parens, calls move ctor
Widget w8{std::move(w4)}; // uses braces, calls std::initializer_list ctor
// (for same reason as w6)
下面的第三个例子说明了,在极端情况下,甚至可能因为编译器倾向选择带有std::initializer_list的重载构造函数,而导致最终编译失败。(原因是编译器发现存在带有std::initializer_list的重载构造函数,而又使用了花括号初始化,并且发现从int(10)或double(5.0)向bool转换是可能的(narrowing conversion),从而调用它,但是这是narrowing conversion,而花括号初始化禁止narrowing conversion,从而最终导致编译失败)
class Widget {
public:
Widget(int i, bool b); // as before
Widget(int i, double d); // as before
Widget(std::initializer_list<bool> il); // element type is now bool
// no implicitconversion funcs
};
Widget w{10, 5.0}; // error!!! requires narrowing conversions
所以只有当没有发生类型转换的可能时,编译器才考虑其他重载的构造函数。
这里编译器会发现不能从int(10)或double(5.0)或bool(true)向std::string发生类型转换,所以最终编译器会找其他最佳匹配的重载构造函数。
class Widget {
public:
Widget(int i, bool b); // as before
Widget(int i, double d); // as before
// std::initializer_list element type is now std::string
Widget(std::initializer_list<std::string> il);// no implicit conversion funcs
};
Widget w1(10, true); // uses parens, still calls first ctor
Widget w2{10, true}; // uses braces, now calls first ctor
Widget w3(10, 5.0); // uses parens, still calls second ctor
Widget w4{10, 5.0}; // uses braces, now calls second ctor
默认构造函数和空的std::initializer_list构造函数
如果既有默认构造函数,又有一个带有std::initializer_list的重载构造函数,那么调用花括号初始化对象时,如果花括号里面是空的,那么调用那个构造函数?
答案是默认构造函数。
这里编译器把空的花括号认为是没有参数,而不是一个空的std::initializer_list。如果想要调用一个空的std::initializer_list来调用带有std::initializer_list参数的重载构造函数,那么就把{}(表示一个空的std::initializer_list)放到一个圆括号中(即({}))或者花括号中({{}})。见下面的例子。
class Widget {
public:
Widget(); // default ctor
Widget(std::initializer_list<int> il); // std::initializer_list ctor
// no implicit conversion funcs
};
Widget w1; // calls default ctor
Widget w2{}; // also calls default ctor
Widget w3(); // most vexing parse! declares a function!
Widget w4({}); // calls std::initializer_list ctor with empty list
Widget w5{{}}; // ditto
vector中经常碰到的区别
在std::vector构造时,经常会碰到使用圆括号和花括号会导致不同初始化的问题,这是由于std::vector有一个接受两个参数的构造函数(参数为个数和每个元素的值),但这会导致使用圆括号和花括号初始化对象,创建为完全不同的两个std::vector。
std::vector<int> v1(10, 20); // use non-std::initializer_list ctor: create 10-element
// std::vector, all elements have value of 20
std::vector<int> v2{10, 20}; // use std::initializer_list ctor: create 2-element
// std::vector, element values are 10 and 20
Scott Meyers提到vector里面的这种设计,后来被认为是错误的。
Scott Meyers提到这两种初始化方式的拥趸的观点,他建议选其中一种,并保持一致即可
Braces-by-default folks are attracted by their unrivaled breadth of applicability, their prohibition of narrowing conversions, and their immunity to C++’s most vexing parse. Such folks understand that in some cases (e.g., creation of a std::vector with a given size and initial element value), parentheses are required. On the other hand, the go-parentheses-go crowd embraces parentheses as their default argument delimiter. They’re attracted to its consistency with the C++98 syntactic tradition, its avoidance of the auto-deduced-a-
std::initializer_listproblem, and the knowledge that their object creation calls won’t be inadvertently waylaid bystd::initializer_listconstructors. They concede that sometimes only braces will do (e.g.,when creating a container with particular values).There’s no consensus that either approach is better than the other, so my advice is to pick one and apply it consistently.
Things to Remember
Braced initialization is the most widely usable initialization syntax, it prevents narrowing conversions, and it’s immune to C++’s most vexing parse.
During constructor overload resolution, braced initializers are matched to
std::initializer_listparameters if at all possible, even if other constructors offer seemingly better matches.An example of where the choice between parentheses and braces can make a significant difference is creating a
std::vector<numeric type>with two arguments.Choosing between parentheses and braces for object creation inside templates can be challenging.
Item 8: Prefer nullptr to 0 and NULL
0 and NULL
理论上,当在需要指针的时候,如果编译器发现只有0可以使用,那么它会(不情愿地)把0当做(空)指针使用。同样地,对待NULL也是如此。可能不同的是,根据具体实现的不同NULL可以被定义为int,long int等。
在C++98中,这可能导致的主要影响是,函数重载会不能匹配到指针类型的重载函数。
void f(int); // three overloads of f
void f(bool);
void f(void*);
f(0); // calls f(int), not f(void*)
f(NULL); // might not compile, but typically calls f(int). Never calls f(void*)
上面f(NULL)可能不能编译的原因是:如果NULL被定义为0L,那么实际上long转int,long转bool,以及0L转void*,对编译器来讲是同样好的,所以会产生歧义(模棱两可)。
C++11 introducednullptr
C++11中引入了nullptr,它的实际类型是std::nullptr_t(which is a wonderfully circular definition)。
std::nullptr_t可以隐式地转换成所有类型的原生指针。
The type
std::nullptr_timplicitly converts to all raw pointer types
在上述例子中,如果存在一种参数是指针类型的重载函数,那么就可以使用nullptr来调用,避免编译器不能匹配想要正确匹配的重载函数了。
/** With examples above **/
f(nullptr); // calls f(void*) overload
使用nullptr而不是0或是NULL可以避免重载函数匹配的问题,除此之外,还可以提高代码可读性,尤其是当何auto一起使用时(It can also improve code clarity, especially when auto variables are involved)。下面的例子说明了,使用nullptr时,可以一眼就发现result实际上是一个指针类型。
auto result = findRecord( /* arguments */ );
if (result == 0) { /* ... */ }
auto result = findRecord( /* arguments */ );
if (result == nullptr) { /* ... */ }
Template with nullptr
假设有以下三个函数,每个的参数都是一种(不同类型的)指针
int f1(std::shared_ptr<Widget> spw); // call these only when
double f2(std::unique_ptr<Widget> upw); // the appropriate
bool f3(Widget* pw); // mutex is locked
如果使用0和NULL,也可以工作(但事实上并不理想)
std::mutex f1m, f2m, f3m; // mutexes for f1, f2, and f3
using MuxGuard = std::lock_guard<std::mutex>; // C++11 typedef; see Item 9
{
MuxGuard g(f1m); // lock mutex for f1
auto result = f1(0); // pass 0 as null ptr to f1
} // unlock mutex
{
MuxGuard g(f2m); // lock mutex for f2
auto result = f2(NULL); // pass NULL as null ptr to f2
} // unlock mutex
{
MuxGuard g(f3m); // lock mutex for f3
auto result = f3(nullptr); // pass nullptr as null ptr to f3
} // unlock mutex
因为看起来代码调用函数的步骤都是类似的,所以可以写成Template的形式(如果是C++14,返回类型可以直接写成decltype(auto))
template<typename FuncType, typename MuxType, typename PtrType>
auto lockAndCall(FuncType func, MuxType& mutex, PtrType ptr) -> decltype(func(ptr)) {
MuxGuard g(mutex);
return func(ptr);
}
那么相应的调用就如下
auto result1 = lockAndCall(f1, f1m, 0); // error!
auto result2 = lockAndCall(f2, f2m, NULL); // error!
auto result3 = lockAndCall(f3, f3m, nullptr); // fine
如上注释中所注明,第一个和第二个调用实际上会编译失败。
第一个:因为0始终都会被编译器认为是int类型,所以模板中ptr会被推导为int类型,但对于f1m而言,它接受的参数却是std::shared_ptr<Widget>,而显然int不能(隐式地)转换成std::shared_ptr<Widget>,所以或编译失败。
第二个:和第一个中的0类似,NULL按照它被定义的类型,或被编译器认为是int或是int-like的类型,这将同样导致编译推导ptr的类型是int或是int-like的类型,而f2m实际上接收的参数类型是std::unique_ptr<Widget>。所以编译失败。
第三个:会编译成功。原因是nullptr本身的类型是std::nullptr_t,这同样也是编译器推导出来的类型,而std::nullptr_t可以隐式地转换成任意一种原生指针(这里的Widget*),所以最后编译通过。
Item 9: Prefer alias declarations to typedef
使用alias declaration而不是typedef的原因
为什么用using alias declaration,而不是老式的(C++98)的typedef,其中就一定有令人信服的技术原因。
it’s reasonable to wonder whether there is a solid technical reason for preferring one over the other.
原因一(主要)
使用
usingalias declaration的主要原因是:template。(typedef是不能对template使用)如果对template使用
usingalias declaration,这时叫做 alias templates。alias declaration can be templatized, in which case they’re called alias templates
With an alias template, it’s a piece of cake.
原因二(次要)
如果是要定义一个函数指针的alias,可以明显看到
usingalias的形式稍微好读一些,但这并不是使用usingalias的形式的主要原因。
// FP is a synonym for a pointer to a function taking an int and
// a const std::string& and returning nothing
typedef void (*FP)(int, const std::string&); // typedef same meaning as above
using FP = void (*)(int, const std::string&); // alias declaration
原因三(次要)
Scott Meyers调侃了一下,如果写个很长的类型名称,会增加得腕管综合征的风险。
Just thinking about it probably increases the risk of carpal tunnel syndrome.
Alias declarations (using) for templates
using name = qualifier vs. typedef
using alias declaration for template的写法
template<typename T> // MyAllocList<T> is synonym
using MyAllocList = std::list<T, MyAlloc<T>>; // for std::list<T, MyAlloc<T>>
而如果使用typedef来写template的alias,就需要在class内部定义类型
template<typename T> // MyAllocList<T>::type
struct MyAllocList { // is synonym for
typedef std::list<T, MyAlloc<T>> type; // std::list<T, MyAlloc<T>>
};
MyAllocList<Widget>::type lw; // client code
template中使用typedef定义的alias会遇到dependent type
更糟糕的是,如果使用typedef,当想在一个template中,声明一个如上用typedef定义的alias,那么就要用到dependent type。
// If use typedef as above, then to use this alias in class Widget
template<typename T>
class Widget { // Widget<T> contains
private: // a MyAllocList<T>
typename MyAllocList<T>::type list; // as a data member
};
前面加上typename关键字的原因是,编译器并不能分辨出MyAllocList<T>::type实际上定义了一个类型,还是别的东西,比如说,一个class的member。
Scott Meyers在解释这个dependent type的时候,举了个例子:
For example, some misguided soul may have concocted something like this:
class Wine { /*something*/ };
template<> // MyAllocList specialization
class MyAllocList<Wine> { // for when T is Wine
private:
enum class WineType { White, Red, Rose };
WineType type; // in this class, type is a data member!
}
这个例子是说,如果特化了MyAllocList这个class(for class Wine),并且在这个特化的class里定义了一个叫做type的成员变量,那么当使用MyAllocList<Wine>::type的时候,就不再是指一个类型,而是一个特化类的成员了!
但是如果使用using name = qualifier形式的alias,情况就不同了
// If use "using name = qualifier: as above, then to use this alias in class Widget
template<typename T>
class Widget {
private:
MyAllocList<T> list; // no "typename", no "::type"
};
可以看到,如果使用using name = qualifier形式的alias,那么在使用这template alias的时候,就不用在前面加typename关键字了。
Scott Meyers解释了,虽然MyAllocList<T>看起来像是dependent type,但实际上编译器遇到MyAllocList知道它是an alias template(而它必须是给类型命名的),所以这里MyAllocList<T>对编译器而言,就是non-dependent type,这时候,既不需要,也不允许添加typename!
使用STL时可能遇到需要添加typename的dependent type
Scott Meyers提到了在C++11 STL中,几种实际上是利用typedef而实现的alias(for template),那么,如果要把它们用于template当中的时候,就需要在它们的前面添加typename关键字而告之编译器,这是类型名。
std::remove_const<T>::type // yields T from const T
std::remove_reference<T>::type // yields T from T& and T&&
std::add_lvalue_reference<T>::type // yields T& from T
C++11的type traits,实际上是由嵌套在template struct里的typedef实现的。是的,就是本节讲的要我们避免使用的typedef。但它这么做,是由历史原因的。
C++11 type traits are implemented as nested typedefs inside templatized structs.
实际上,在C++14 STL中,每个对应的type traits都有一个使用using name = qualifier实现的alias template,从而可以不需要在template中使用时,前面加上typename了。(都是是对应的名字后面加上后缀_t)。
std::remove_const<T>::type // C++11: const T → T
std::remove_const_t<T> // C++14 equivalent
std::remove_reference<T>::type // C++11: T&/T&& → T
std::remove_reference_t<T> // C++14 equivalent
std::add_lvalue_reference<T>::type // C++11: T → T&
std::add_lvalue_reference_t<T> // C++14 equivalent
Scott Meyers建议使用C++14的写法,并提到如何在C++11中使用C++14的写法(虽然不是C++14的实现)
template <class T> using remove_const_t = typename remove_const<T>::type;
template <class T> using remove_reference_t = typename remove_reference<T>::type;
template <class T> using add_lvalue_reference_t = typename add_lvalue_reference<T>::type;
template metaprogramming = TMP
Things to Remember
typedefs don’t support templatization, but alias declarations do.Alias templates avoid the
::typesuffix and, in templates, thetypenameprefix often required to refer to typedefs.C++14 offers alias templates for all the C++11 type traits transformations.
Item 10: Prefer scoped enums to unscoped enums
compile constant :编译时常量
C++11风格的scoped enum的优点
C++11, scoped enum
C++98, unscoped enum
和C++98风格的enum(对应地,被称做unscoped enum,正式用语)相比,C++11风格的scoped enum主要有三大优点
1. C++11风格的enum class限定了作用范围
C++98风格的enumerator的名字属于它所被定义的scope中,这意味着在同一个scope中,不能再有(和enumerator里对应名字)相同的名字,否则会导致重命名问题(namespace pollution)。
而C++11风格的enum,它所定义的enumerator names并不会泄露(leak into)到这个enum class所定义的作用域中,这意味着在同一个作用域中,可以有和enum class里面的enumerator name相同的名字。
// C++98 style enumerator
enum Color { black, white, red }; // black, white, red are in same scope as Color
auto white = false; // error! white already declared in this scope
// C++11 style enumerator
enum class Color { black, white, red }; // black, white, red are scoped to Color
auto white = false; // fine, no other "white" in scope
Color c = white; // error! no enumerator named "white" is in this scope
Color c = Color::white; // fine
auto c = Color::white; // also fine (and in accord with Item 5's advice)
需要注意的是,如果要使用enum class中所定义的enumerator names,必须在前面加上enumerator的限定(如Color::white)
2. C++11风格的enum class的枚举变量不会隐式转换成integral types
C++11风格的enum class的枚举变量是强类型的,它们不会隐式地转换成整型(或long等),因此,它们也不会隐式地转换成比如floating的其他类型。
enum Color { black, white, red }; // unscoped enum
std::vector<std::size_t> primeFactors(std::size_t x); // func. returning
// prime factors of x
Color c = red;
if (c < 14.5) { // compare Color to double (!)
auto factors = primeFactors(c); // compute prime factors of a Color (!)
}
上面的例子中,C++98风格的enum(unscoped enum)的enumerator会发生隐式地转换,从而和floating point做比较,实际上这并不是所期望的。
如果使用scoped enum(C++11风格),那么上述的代码就会编译失败,从而提醒书写者做修改。
如果书写者原本的意图就是要和floating做对比,那么就使用static_cast<double>进行转换。
3. C++11风格的enum class的可以直接先声明后定义
在C++11中,实际上scoped enum和unscoped enum都可以进行先声明后定义。
但区别在于,unscoped enum必须在声明的时候,同时指明其潜在的类型(specify the underlying type),scoped enum在声明的时候即可以指定其潜在的类型,也可以不指定其潜在的类型。
unscoped enum是C++98中的,编译器要做优化(使用最少的bit来容纳所定义的enumerator,比如使用char),所以需要提前知道它的类型(即大小)。C++11中对此做了提高,就可以在声明的时候就得出其所需的类型(即bit大小,默认是int)。
// C++98 style enumerator forward declaration
enum Status: std::uint32_t;
// C++1 style enumerator forward declaration
enum class Status; // forward declaration
enum class Status: std::uint32_t; ; // forward declaration, now the underlying type
// for Status is std::uint32_t (from <cstdint>)
更适合unscoped enum的场景
虽然一般情况下,最好使用scoped enum,但少数情况下也许unscoped enum也有用武之地。
Scott Meyers提到了一种,即使用std::tuple。
因为std::tuple定义了之后,在获取其中的元素值时,需要使用std::get<N>,这里的N是从0开始的整数。
那么由于scoped enum中的enumerators是强类型,不能隐式转换成integral types,因此unscoped enum就可以直接使用而发生隐式的转换,从而简洁地完成。比如std::get<FIRST>。
那么为什么要用enum?因为这样可以给每个位置一个直观的名字,否则0、1、2这些,谁也不知道代表什么含义。
Things to Remember
C++98-style
enums are now known as unscopedenums.Enumerators of scoped
enums are visible only within theenum. They convert to other types only with a cast.Both scoped and unscoped
enums support specification of the underlying type. The default underlying type for scopedenums is int. Unscopedenums have no default underlying type.Scoped
enums may always be forward-declared. Unscopedenums may be forward-declared only if their declaration specifies an underlying type.
Item 11: Prefer deleted functions to private undefined ones
C++98声明不可用函数
为了防止某些函数被使用(通常是copy-constructor和copy assignment operator),在C++98中,可以声明它们为private,但是不定义它们。
比如basic_ios的声明
template <class charT, class traits = char_traits<charT> >
class basic_ios : public ios_base {
public:
// ...
private:
basic_ios(const basic_ios& ); // not defined
basic_ios& operator=(const basic_ios&); // not defined
};
C++11声明不可用函数
在C++11中,可以使用delete关键字,来声明一个函数不可使用。
使用delete关键字标记的函数,最好放在public作用域中,否则有的编译器可能会报告是private或者不起作用(没有能被编译器识别为delete函数)。
template <class charT, class traits = char_traits<charT> >
class basic_ios : public ios_base {
public:
// ...
basic_ios(const basic_ios& ) = delete;
basic_ios& operator=(const basic_ios&) = delete;
// ...
};
C++11做法的优点
比起C++98声明为一个private成员函数,C++11标记为
delete的函数,不仅不能在class之外使用,而且在class内或friend class里也不可使用。和C++98的做法相比,
delete关键字不仅可以用于类的成员函数,还可以使用在非类的成员函数上。比如,有函数
bool isLucky(int number);,它接收int类型的参数,但实际上有char、bool等可以隐式转换成int,导致一些可能非预期的调用。为了避免这些情况,就可以把这些对应的函数标记为delete
bool isLucky(int number); // original function
bool isLucky(char) = delete; // reject chars
bool isLucky(bool) = delete; // reject bools
bool isLucky(double) = delete; // reject doubles and floats
上面定义的bool isLucky(double) = delete;,之所以也会导致float类型的overload函数也被delete,原因是,在从float向int或double转换的时候,C++会倾向于转换为double而不是int。因此如果调用float类型的overload,实际上会调用double的overload函数。
另外的一个
delete函数可以做到,但C++98风格的private函数做不到的是,可以禁止使用本应该被禁止的template instantiation。
template<typename T>
void processPointer(T* ptr);
template<>
void processPointer<void>(void*) = delete;
template<>
void processPointer<char>(char*) = delete;
template<>
void processPointer<const void>(const void*) = delete;
template<>
void processPointer<const char>(const char*) = delete;
如上,在处理指针类型的template的时候,有两种指针是特殊的角色,需要特殊处理。即void*已经char*。
void*指针不能解引用,也不能自增或自减。而char*通常代表C风格的字符串。这两种通常需要特殊处理。
所以可以如上声明delete函数。
还有一个优点:一个在class内的template function,如果需要把它的某个特化禁用,只能用C++11的
delete。这是由于,C++98风格的禁用函数,其声明需要是
private,但模板的特化又必须在namespacescope,因此会编译失败。而C++11风格的禁用函数,就可以将其声明在class scope之外(同时也声明是delete)
class Widget {
public:
template<typename T>
void processPointer(T* ptr) { /*...*/ }
};
template<> // still public,
void Widget::processPointer<void>(void*) = delete; // but deleted
Things to Remember
Prefer deleted functions to private undefined ones.
Any function may be deleted, including non-member functions and template instantiations.
Item 12: Declare overriding functions override
override 函数覆盖(子类函数覆盖父类函数)
overload 函数重载
C++11中函数覆盖的条件
函数覆盖(子类函数覆盖父类函数)需要满足的条件
父类函数需要标记为
virtual父类和子类的函数名必须相同
父类和子类函数的参数类型必须相同
父类和子类函数的
const性质必须相同父类和子类函数的返回值类型和异常必须兼容
父类和子类函数的引用修饰(reference qualifiers)必须也相同(C++11引入)
关于最后一项引用修饰(reference qualifiers),指的是成员函数是否能被 lvalue 或 rvalue 的对象所调用。
如下,带有&修饰和&&修饰的成员函数,可以有同样的名字、参数类型和返回值。
其中,带有&修饰的函数,必须由左值对象调用;带有&&修饰的函数,必须由右值对象调用;
class Widget {
public:
void doWork() &; // this version of doWork applies only when *this is an lvalue
void doWork() &&; // this version of doWork applies only when *this is an rvalue
};
Widget makeWidget(); // factory function (returns rvalue)
Widget w; // normal object (an lvalue)
w.doWork(); // calls Widget::doWork for lvalues (i.e., Widget::doWork &)
makeWidget().doWork(); // calls Widget::doWork for rvalues (i.e., Widget::doWork &&)
Scott Meyers举了个例子,列出了以下实际上没有发生函数覆盖的原因
class Base {
public:
virtual void mf1() const;
virtual void mf2(int x);
virtual void mf3() &;
void mf4() const;
};
class Derived: public Base {
public:
virtual void mf1();
virtual void mf2(unsigned int x);
virtual void mf3() &&;
void mf4() const;
};
mf1is declaredconstinBase, but not inDerived.mf2takes an int inBase, but an unsigned int inDerived.mf3is lvalue-qualified inBase, but rvalue-qualified inDerived.mf4isn’t declared virtual inBase.
Scott在这里想要说明的是,class overrides写正确了很重要,但很容易写错。
C++11引入override关键字
override关键字的作用
使编译器识别哪些函数是意图用作
overrides,但实际上在子类中没有正确实现。如果想要在父类中修改函数signature,如果有
override关键字,可以在修改之后由编译器体现产生的影响大小(错误多少)override关键字只有出现在成员函数声明的末尾时,才会起表名函数覆盖的作用,否则,它也可以当做正常的函数名(变量名等)使用。
class Warning { // potential legacy class from C++98
public:
void override(); // legal in both C++98 and C++11 (with the same meaning)
};
成员函数的&和&&修饰
Scott Meyers举例说明了,在某些情况下,使用&&修饰一个成员函数,可以避免不必要的拷贝
class Widget {
public:
using DataType = std::vector<double>;
DataType& data() { return values; }
private:
DataType values;
};
Widget makeWidget() {
/* ... */ // This function returns an object (rvalue) in the end.
}
Widget w;
auto vals1 = w.data(); // copy w.values into vals1
auto vals2 = makeWidget().data(); // copy values inside the Widget into vals2
w是一个左值,w.data()返回的是一个左值引用,而左值引用同样是左值,所以编译器会使用拷贝构造函数来初始化vals1。makeWidget()返回的是一个右值,但Wideget::data()返回的是一个左值引用,编译器还是会按照字面理解,从而调用拷贝构造函数来初始化vals2。但实际上
makeWidget()返回的是一个右值(实际上C++14里它是将亡值xvalue),那么把这个右值里面的std::vector拷贝到一个新的object中,实际上是没有必要的(因为右值即将被销毁),所以更好的办法是调用移动构造函数。
改进如下,即同时定义了&和&&修饰符限定的成员函数,以此来告之编译器左值对象来调用&成员函数,而右值对象来调用&&成员函数。
class Widget {
public:
using DataType = std::vector<double>;
DataType& data() & { return values; } // for lvalue Widgets, return lvalue
DataType data() && { return std::move(values); } // for rvalue Widgets, return rvalue
private:
DataType values;
};
Widget w;
auto vals1 = w.data(); // calls lvalue overload for Widget::data,
// copy-constructs vals1
auto vals2 = makeWidget().data(); // calls rvalue overload for Widget::data,
// move-constructs vals2
Things to Remember
Declare overriding functions
override.Member function reference qualifiers make it possible to treat
lvalueandrvalueobjects(*this)differently.
Item 13: Prefer const_iterators to iterators
C++98中的const_iterator不实用
虽然C++98中也有const_iterator,但是它并不实用,Scott举例进行了说明。
比如想在一个vector中查找1983出现的地方,并且插入1998。一般地,C++98的写法如下:
std::vector<int> values;
std::vector<int>::iterator it = std::find(values.begin(),values.end(), 1983);
values.insert(it, 1998);
这里,实际上对原先vector中的元素没有进行任何修改,所以const_iterator是比iterator更好的选择,但是如果要在C++98中使用const_iterator,那么就需要改写如下:
typedef std::vector<int>::iterator IterT; // typedefs
typedef std::vector<int>::const_iterator ConstIterT;
std::vector<int> values;
ConstIterT ci = std::find(static_cast<ConstIterT>(values.begin()), // cast
static_cast<ConstIterT>(values.end()), 1983);// cast
values.insert(static_cast<IterT>(ci), 1998); // may not compile
这里的问题在于
从一个non-
const容器中,得到一个const_iterator不太容易,因为
std::vector::insert需要的是一个iterator(C++98),而把一个const_iterator转换成iterator可能会编译失败(static_cast和reinterpret_cast甚至也不行)
最终,C++98中,const_iterator不那么实用
C++11提升了对const_iterator的支持
C++11中就可以从一个container(包括non-const)中容易地得到一个const_iterator,而且STL的成员函数(比如insert和erase)也实用const_iterator。
std::vector<int> values; // as before
auto it = std::find(values.cbegin(),values.cend(), 1983); // use cbegin and cend
values.insert(it, 1998);
C++11中const_iterator的缺憾
C++11中const_iterator的一大缺憾是,它给container或container-like的数据结构提供了begin和end的non-member function,但是没有提供cbegin和cend的non-member function。(C++14中做了改进)
这会使得在有些情况下,如果要写模板的时候会比较麻烦。比如有如下的模板函数
// in container, find first occurrence of targetVal, then insert insertVal
template<typename C, typename V>
void findAndInsert(C& container, const V& targetVal, const V& insertVal)
{
using std::cbegin;
using std::cend;
// Use non-member cbegin & cend
auto it = std::find(cbegin(container), cend(container), targetVal);
container.insert(it, insertVal);
}
实际上,因为C++11没有提供cbegin,cend,rbegin,rend,crbegin以及crend(C++14纠正了这一短视的疏忽),所以上面的代码在C++11中会编译失败。
Scott Meyers提供了在C++11中,给这类container的一个non-member function。
template <class C>
auto cbegin(const C& container)->decltype(std::begin(container))
{
return std::begin(container); // see explanation below
}
第一眼看上去会很意外,因为它没有调用container的成员函数cbegin。Scott Meyers做了解释
第一,container这个参数有可能是一个container-like的数据结构,有
begin成员函数,但没有cbegin成员函数。第二,因为container是
const &,而std::begin在作用于const类型的容器上时,会生成const_iterator。
Things to Remember
Prefer
const_iteratorsto iterators.In maximally generic code, prefer non-member versions of
begin,end,rbegin, etc., over their member function counterparts.
Item 14: Declare functions noexcept if they won’t emit exceptions.
C++11和C++98异常声明的不同
因为改变C++98中的exception specification,可能会导致client code(因为用户可能会依赖这个exception specification而编写代码),所以C++98中的exception specification用处不像想象中的那么大(因为你需要总结可能抛出异常的类型)。
C++11中,加入了noexcept,能保证该函数不会抛出异常(即非黑即白,就两种情况:抛或不抛),从而使得编译器在发现万一有异常时,能够报错提醒。
int f(int x) throw(); // no exceptions from f: C++98 style
int f(int x) noexcept; // no exceptions from f: C++11 style
C++11比C++98异常声明可以优化编译结果
C++98的异常在runtime时发生:
函数调用栈会被展开给调用者(caller)
(调用者或其他)进行一些处理
程序结束运行
C++11的异常在runtime时发生:
和C++98相比,调用栈可能会(possibly)被展开给调用者(caller),然后再结束运行
所以C++11的noexcept带来的潜在好处是
(可能)不必要保留调用栈的信息
不需要保证
noexcept函数里面的object是按照逆序的顺序依次析构
RetType function(params) noexcept; // most optimizable
RetType function(params) throw(); // less optimizable
RetType function(params); // less optimizable
std::vector和std::pair用到的noexcept
std::vector::push_back的noexcept
std::vector::push_back在C++98中是保证不抛出异常的。但它的潜在问题是,可能会发生扩容。一旦发生扩容,那么就需要把原来vector里的东西拷贝到新分配的内存中取,那么拷贝构造就比较耗费时间(比如,每个元素的拷贝实际上很花时间)
C++11中引入了移动语义(move semantic),所以可以优化。比如发生扩容的时候,就可以把原先内存上的元素通过移动语义,“移动”到新的内存上去(需要元素支持移动语义),这样就能提升性能。
但通过移动语义产生的潜在问题是:如果移动前n个元素没问题,但移动第n+1个元素是发生了异常,这时候前n个元素已经被修改,没有办法复原旧内存上的这n个元素,因为把新内存上的元素再视图移动回去时,还是可能发生异常。
所以std::vector::push_back的做法是:能move就move,但如果不能,就copy。
但能不能move就需要保证不跑异常。那么依靠什么来保证?答案是通过函数声明的noexcept。
std::vector::push_backtakes advantage of this “move if you can, but copy if you must” strategy,
std::pair::swap的noexcept
std::pair::swap是另一种风格的异常保证:依赖于需要交换两个元素的交换函数是否被声明成了noexcept,即条件依赖的noexcept声明。
// Swapping 2 arrays
template <class T, size_t N>
void swap(T (&a)[N], T (&b)[N]) noexcept(noexcept(swap(*a, *b)));
// Swapping 2 arrays
template <class T1, class T2>
struct pair {
void swap(pair& p) noexcept(noexcept(swap(first, p.first)) &&
noexcept(swap(second, p.second)));
};
第一个函数,是用来实现两个数组的交换,它是不是noexcept,依赖于交换两个数组中的元素的操作是否是noexcept。
第二个函数,是std::pair的swap,它的noexcept,是依赖于分别交换first和second的操作是否是noexcept。
要不要noexcept?
实际上比起noexcept带来的编译优化的好处,程序的正确性更重要,并且,一个函数(通常叫做exception-neutral)里面实际上也很有可能调用其他会抛出异常的函数。
所以Scott Meyers也说了,为了将一个函数声明成noexcept,而去修改函数的逻辑实现,这就变成了本末倒置。
Twisting a function’s implementation to permit a
noexceptdeclaration is the tail wagging the dog. Is putting the cart before the horse. Is not seeing the forest for the trees. Is…choose your favorite metaphor
C++98认为,释放内存的函数和析构函数如果抛异常,是一种不好的风格。
C++11中默认的,和内存释放相关的函数,以及所有的析构函数(包括用户定义的和编译器生成的),都被隐式地声明成为了noexcept。(可以手动加上noexecpt,但不符合传统,所以就不用自己加)
By default, all memory deallocation functions and all destructors—both user-defined and compiler-generated—are implicitly
noexcept.
但有一种情况,destructor不是被隐式地声明为noexecept,这种情况是:有成员的析构函数被显示地声明成了noexcept(false),即可能会抛出异常。C++11中,STL里面没有这样的析构函数。
Wide contract和narrow contract
什么是Wide contract function?
没有先决条件
不论程序状态如何,都可以调用
对传入的参数没有限制约束
不会出现未定义的情况(undefined behavior)
什么是narrow contract function?
不满足wide contract的function
如果违反了先决条件,结果就可能是未定义(undefined behavior)
noexcept函数可以调用实际上有exception的函数
Scott Meyers最后举例,说明实际上编译对于声明了noexcept的函数,如果调用实际上会抛异常的函数,也会编译通过。
void setup(); // functions defined elsewhere
void cleanup();
void doWork() noexcept {
setup(); // set up work to be done do the actual work
cleanup(); // perform cleanup actions
}
出现这样看似矛盾的情况的原因:
被调用的函数可能是C写的(没有C++中的
noexcept保证)是C++98中的函数,没有使用C++11的exception specification,但还没有改为C++11的形式
Things to Remember
noexceptis part of a function’s interface, and that means that callers may depend on it.
noexceptfunctions are more optimizable than non-noexcept functions.
noexceptis particularly valuable for the move operations, swap, memory deallocation functions, and destructors.Most functions are exception-neutral rather than
noexcept.
Item 15: Use constexpr whenever possible.
constexpr
用于变量时,通常不意味一个值是常量(
const),而是它在编译期间已知(Conceptually,constexprindicates a value that’s not only constant, it’s known during compilation. )用于函数时,更多是,它是一种特性(feature),详细解释见下。
constexpr on objects
通常认为一个object被声明为constexpr,就意味着它的值在编译期间就已知(实际上是在translation期间,因为translation不仅包括编译,还包括链接),好处是它们可以放在只读的内存位置上。
通常可以声明为constexpr的对象(或值)
array sizes
integral template arguments (including lengths of
std::arrayobjects)enumerator values
alignment specifiers, and more.
通常,constexpr就是const,但const不一定是constexpr。(Simply put, all constexprobjects are const, but not all constobjects are constexpr.)
constexpr on functions
当constexpr用于函数的时候,正确的理解是这样的:
constexpr函数可以用在需要编译期常量的上下文中(注意这个是前提:即需要编译期间常量的环境)。如果传入的函数参数值是编译期可知的常量,那么函数的结果就在编译期间被计算生成。如果传入的函数参数值不是编译期可知的常量,那么编译失败。(如果不是在需要编译期间常量的环境中时)如果
constexpr函数是被一个(或多个)编译期间不可知的值所调用,那么这个constexpr函数就像一个普通的函数一样,在运行时计算结果。(意味着不需要两个版本的函数,一个给编译期间用,一个给运行时用)
简言之,在需要编译期间常量的地方,constexpr函数的参数必须也是编译期间常量,在不需要编译期间常量的地方,constexpr函数的参数既可以是编译期间常量,也可以不是编译期间常量。
C++11成员函数如果是constexpr,那么它也会同时被隐式地声明为const。所以一般getter可以是constexpr,但setter不行(C++14放松了限制)
一个既能编译期计算又能运行时计算的函数例子
在C++11中,constexpr函数里(最多)只能有一个return语句,而C++14放松了这个限制。所以C++11中可以使用三元运算符(和递归模拟循环)来绕开这个限制。
比如,需要一个编译期间计算幂值的函数。
// C++11 constexpr function allows no more than one executable statement: a return
constexpr int pow(int base, int exp) noexcept {
return (exp == 0 ? 1 : base * pow(base, exp - 1));
}
// C++14 restrictions are looser
constexpr int pow(int base, int exp) noexcept // C++14 {
auto result = 1;
for (int i = 0; i < exp; ++i) result *= base;
return result;
}
因为constexpr函数,它可以用在需要编译期间常量的上下文中,所以可以指定数组的大小。
当然,条件是:需要参数也是编译期间可知的
constexpr auto numConds = 5; // # of conditions
std::array<int, pow(3, numConds)> results; // results has 3^numConds elements
当然,constexpr函数也可以用在不需要编译期间常量的上下文中,这时候参数可以是编译期间可知的,也可以是运行期间可知的,它们分别产生编译期间就可知的结果,以及只有运行期期间可知的结果。下面就是一个编译期间计算结果环境的使用该函数。
auto base = readFromDB("base"); // get these values
auto exp = readFromDB("exponent"); // at runtime
auto baseToExp = pow(base, exp); // call pow function at runtime
可以是constexpr的object
C++11中所有的built-in types(除void外)都是literal type,所以可以声明为
constexpr自定义的类也可以是
constexpr(因为构造函数和成员函数也可以是constexpr)
一个自定义类可以是constexpr的例子
class Point {
public:
constexpr Point(double xVal = 0, double yVal = 0) noexcept: x(xVal), y(yVal) {}
constexpr double xValue() const noexcept { return x; }
constexpr double yValue() const noexcept { return y; }
void setX(double newX) noexcept { x = newX; }
void setY(double newY) noexcept { y = newY; }
private:
double x, y;
};
这里,因为Point构造函数的两个参数可以是编译期间常量,所以这个构造函数可以声明为constexpr。这样创建的Point object也是编译期间的常量。
constexpr Point p1(9.4, 27.7); // fine, "runs" constexpr ctor during compilation
constexpr Point p2(28.8, 5.3); // also fine
成员函数xValue()和yValue(),因为可以使用一个constexpr object来调用它们,所以它们也可以是constexpr。
可以利用这两个getter的这个性质,写出下面的函数,并初始化另一个constexpr object。
constexpr Point midpoint(const Point& p1, const Point& p2) noexcept {
return { (p1.xValue() + p2.xValue()) / 2, // call constexpr
(p1.yValue() + p2.yValue()) / 2 }; // member funcs
}
constexpr auto mid = midpoint(p1, p2); // init constexpr object w/result of
// constexpr function
在C++11中,两个setter是不能声明为constexpr的,原因是
它们会修改对象,而
constexpr成员函数会被隐式地声明为const返回值类型是
void,但void不是literal type
但C++14中解除了这个限制,所以只要setter也可以声明为constexpr。(只要stter函数的参数也是编译期间可知的,那么它们也是编译期间就可计算的)
class Point {
public:
// ...
constexpr void setX(double newX) noexcept { x = newX; } // C++14
constexpr void setY(double newY) noexcept { y = newY; } // C++14
};
那么也可以利用这样的setter来写出另外的constexpr函数
// (Valid since C++14) return reflection of p with respect to the origin
constexpr Point reflection(const Point& p) noexcept {
Point result; // create non-const Point
result.setX(-p.xValue()); // set its x and y values
result.setY(-p.yValue());
return result; // return copy of it
}
// Use
constexpr Point p1(9.4, 27.7);
constexpr Point p2(28.8, 5.3);
constexpr auto mid = midpoint(p1, p2);
constexpr auto reflectedMid = reflection(mid); // reflectedMid's value is
// (-19.1 -16.5) and known
// during compilation
Things to Remember
constexprobjects areconstand are initialized with values known during compilation.
constexprfunctions can produce compile-time results when called with arguments whose values are known during compilation.
constexprobjects and functions may be used in a wider range of contexts than non-constexprobjects and functions.
constexpris part of an object’s or function’s interface.
Item 16: Make const member functions thread safe.
本节主要讲的是,在const成员函数中,如果有mutable变量,那么在多线程环境中,修改此mutable变量将可能引起一些的意外情况,以及如何处理的措施。
本节,Scott Meyers主要通过举例进行了说明。
mutable成员变量
mutable 关键字用在成员变量上,可以突破const成员函数的限制,在const成员函数修改这个类的成员变量,但理论上,它不应该修改可以改变这个类的状态的成员变量,所以需要类的定义者拿捏和把握。
修改mutable成员变量的const成员函数
有一个const成员函数,会修改mutable成员变量。如果这个函数被多个线程调用,很显然,变量rootsAreValid和rootVals的结果会发生问题。
class Polynomial {
public:
using RootsType = std::vector<double>;
RootsType roots() const {
if (!rootsAreValid) { // if cache not valid
/* ... */ // compute roots, store them in rootVals
rootsAreValid = true;
}
return rootVals;
}
private:
mutable bool rootsAreValid{ false };
mutable RootsType rootVals{};
};
使用std::mutex
为了解决前面提到的data racing问题,解决的办法有二(如下),但不管那种,如果定义了std::mutex或者std::atomic作为成员变量,那么这个类的对象就不可拷贝,只能移动了(not copyable,move-only)
使用
std::mutex使用
std::atomic(或对应的concurrentvariables)
// Use mutex to resolve data racing issues
class Polynomial {
public:
using RootsType = std::vector<double>;
RootsType roots() const {
std::lock_guard<std::mutex> g(m); // lock mutex <-------
if (!rootsAreValid) { // if cache not valid
/* ... */ // compute roots, store them in rootVals
rootsAreValid = true;
}
return rootVals;
}
private:
mutable std::mutex m; // mutex <-------
mutable bool rootsAreValid{ false };
mutable RootsType rootVals{};
};
使用std::atomic
但有时候使用std::mutex开销比较大,这时候std::atomic是更好的选择。
比如有一个计算调用次数的成员函数,可以使用std::atomic变量,缓解加锁解锁的性能问题。
class Point { // 2D point
public:
double distanceFromOrigin() const noexcept {
++callCount; // atomic increment
return std::sqrt((x * x) + (y * y));
}
private:
mutable std::atomic<unsigned> callCount{ 0 };
double x, y;
};
使用多个std::atomic的可能问题
假设定义了如下的类,有成员函数和成员变量。
class Widget {
public:
int Widget::magicValue() const;
private:
mutable std::atomic<bool> cacheValid{ false };
mutable std::atomic<int> cachedValue;
};
成员函数Widget::magicValue() 的实现有两种办法
第一种办法
int Widget::magicValue() const {
if (cacheValid) return cachedValue;
else {
auto val1 = expensiveComputation1();
auto val2 = expensiveComputation2();
cachedValue = val1 + val2; // uh oh, part 1
cacheValid = true; // uh oh, part 2
return cachedValue;
}
}
第二种办法
int Widget::magicValue() const
{
if (cacheValid) return cachedValue;
else {
auto val1 = expensiveComputation1();
auto val2 = expensiveComputation2();
cacheValid = true; // uh oh, part 1
return cachedValue = val1 + val2; // uh oh, part 2
}
}
第一种办法的问题是,
如果一个线程发现
cacheValid是false,然后开始做计算,然后把计算结果赋值给cachedValue,但还没有把cacheValid修改为true此时,有另外一个(或者好多个)线程查看发现
cacheValid是false,然后也都开始做计算,那么实际上这时候,重复的计算就没有避免,这个cache的设计就失效了。
第二种办法的问题是,
如果一个线程发现
cacheValid是false,然后首先把cacheValid修改为true,但还没有来得及修改cachedValue此时,有另外一个(或者好多个)线程查看发现
cacheValid是true,然后直接就误认为cachedValue已经算好了,就直接拿它返回,实际上返回的是错误的值
那么在这种情况下,正确的做法就是使用std::mutex
class Widget {
int magicValue() const {
std::lock_guard<std::mutex> guard(m); // lock m
if (cacheValid) return cachedValue;
else {
auto val1 = expensiveComputation1();
auto val2 = expensiveComputation2();
cachedValue = val1 + val2;
cacheValid = true;
return cachedValue;
}
}
private:
mutable std::mutex m;
mutable std::atomic<bool> cacheValid{ false };
mutable std::atomic<int> cachedValue;
}
Things to Remember
Make
constmember functions thread safe unless you’re certain they’ll never be used in a concurrent contextUse of
std::atomicvariables may offer better performance than amutex, but they’re suited for manipulation of only a single variable or memory location.
Item 17: Understand special member function generation.
special member function指的是C++编译器愿意帮助生成的特殊成员函数。它们仅仅在需要的时候才会被编译器生成。
the special member functions are the ones that C++ is willing to generate on its own
These functions are generated only if they’re needed
C++98 special member function
C++98有四种special member function
The default constructor
The destructor
The copy constructor
The copy assignment operator
对于默认构造函数,只有你不提供任何的构造函数的时候,编译器才会帮助生成。否则哪怕只有一个构造函数是接受参数的,那么编译器就不会帮助生成默认构造函数。
编译器生成的这些特殊成员函数,默认是public和inline,并且不是virtual。
除非子类所继承的父类有析构函数是virtual,那么编译器生成的子类析构函数也是virtual。
C++11 special member function
C++11除了C++98中的四种特殊成员函数之外,还有两个
The move constructor
The move assignment operator
移动构造函数和移动赋值操作符,类似拷贝构造函数,仅在需要时被编译器生成。
移动构造函数的执行,也是类似拷贝构造函数,即对每个non-static成员变量执行”memberwise moves”。(对每个成员执行移动构造)。
移动赋值操作符,也是对每个non-static成员变量执行”move assignment”。(对每个成员执行移动赋值)。
如果有基类,那么也移动构造(或移动赋值)其基类部分。
虽然移动构造和移动赋值采用的是”memberwise moves”,但如果其成员没有提供移动构造或移动赋值,实际上是用的是拷贝构造或拷贝复制。所以”memberwise moves”更多是一种request。
Copy operation interacts move operation
拷贝构造和拷贝赋值不相互冲突:定义了拷贝构造函数,没有定义拷贝赋值操作符,但如果需要,编译器还是会帮助生成拷贝赋值操作符。同样地,定义拷贝赋值操作符,没有定义拷贝构造函数,但如果需要,编译器还是会帮助生成拷贝赋值操作符。
移动构造和移动赋值相互冲突:定义了移动构造函数,没有定义移动赋值操作符,那么编译器就不会帮助生成移动赋值操作符。反之同理。原因是编译器认为有自定义的拷贝构造,那么就暗示移动构造就和一般的memberwise moves不同,也就不适用于移动赋值操作符。反过来也一样。
如果显示定义了拷贝构造函数(或拷贝赋值),那么也编译器也不会再生成移动构造和移动赋值。原因是,编译器认为既然你定义了拷贝构造,那么普通的memberwise copy就不适用了,那么进一步推理,memberwise moves也就不适用了,所以就不再生成了。
类似的,如果显示定义了移动构造(或移动赋值),那么也编译器也不会再生成拷贝构造函数和拷贝赋值,原因同上。
Rule of Three
如果你定义了以下任何一个,那么这三个就应该被全部定义(原因是和内存管理相关)
The copy constructor
The copy assignment operator
The destructor
实际上在C++98中,如果你定义了一个destructor,就意味着,内存管理可能是你自定义的操作,所以理论上就不该再由编译器生成copy operation,但C++98中没有对此做出限制。C++11也没有做出限制的原因是,怕破坏太多的历史遗留代码。
但对于move operation,C++11更新了这一点:如果有一个自定义的destructor,那么编译器就不再会生成move operation(即移动构造和移动赋值)
Move operation被编译器生成的条件
No copy operations are declared in the class.
No move operations are declared in the class.
No destructor is declared in the class.
一个潜在影响性能的例子
class StringTable {
public:
StringTable() { makeLogEntry("Creating StringTable object"); } // added
~StringTable() { makeLogEntry("Destroying StringTable object"); }// also
// other funcs
}
因为有自定义的析构函数(destructor),那么编译器就不再生成移动构造函数和移动赋值操作符。代码虽然可以编译通过,并且功能也正确,但实际上这个类的一个对象,如果被要求“移动“时,实际上编译器会使用拷贝操作来代替,这样就降低了性能。
C++11中特殊成员函数的生成规则
默认构造函数
没有用户定义的构造函数时,才由编译器生成。
析构函数
编译器生成的析构函数,默认是
noexcept,并且只有当基类是virtual的时候,才会声明为virtual拷贝构造函数
没有用户定义的拷贝构造时,才由编译器生成。
如果有移动构造或移动赋值,就会被声明为
delete。如果有用户自定义的拷贝构造或析构函数时,就不会再由编译器生成。
拷贝赋值操作符
没有用户定义的拷贝赋值时,才由编译器生成。
如果有移动构造或移动赋值,就会被声明为
delete。如果有用户自定义的拷贝赋值或析构函数时,就不会再由编译器生成。
移动构造函数和移动赋值操作符
当有用户自定义的拷贝操作(拷贝构造和拷贝赋值),移动操作(移动构造和移动赋值)和析构函数时,编译器就不再生成。
Default constructor: Same rules as C++98. Generated only if the class contains no user-declared constructors.
Destructor: Essentially same rules as C++98; sole difference is that destructors are
noexceptby default. As in C++98, virtual only if a base class destructor is virtual.Copy constructor: Same runtime behavior as C++98: memberwise copy construction of non-
staticdata members. Generated only if the class lacks a user-declared copy constructor. Deleted if the class declares a move operation. Generation of this function in a class with a user-declared copy assignment operator or destructor is deprecated.Copy assignment operator: Same runtime behavior as C++98: memberwise copy assignment of non-
staticdata members. Generated only if the class lacks a user-declared copy assignment operator. Deleted if the class declares a move operation. Generation of this function in a class with a user-declared copy constructor or destructor is deprecated.Move constructor and move assignment operator: Each performs memberwise moving of non-
staticdata members. Generated only if the class contains no user-declared copy operations, move operations, or destructor.
特殊成员函数生成规则的罕见例外
当有类似于拷贝构造(或拷贝赋值或其它)的template函数时,如果满足需要的条件,编译器仍然会生成拷贝构造(和拷贝和其它),哪怕template函数在实例化之后会产生相同的函数signature。Scott Meyers会在item26中说明这一情况。
class Widget {
template<typename T> // construct Widget
Widget(const T& rhs); // from anything
template<typename T> // assign Widget
Widget& operator=(const T& rhs); // from anything
};
Things to Remember
The special member functions are those compilers may generate on their own: default constructor, destructor, copy operations, and move operations.
Move operations are generated only for classes lacking explicitly declared move operations, copy operations, and a destructor.
The copy constructor is generated only for classes lacking an explicitly declared copy constructor, and it’s deleted if a move operation is declared. The copy assignment operator is generated only for classes lacking an explicitly declared copy assignment operator, and it’s deleted if a move operation is declared. Generation of the copy operations in classes with an explicitly declared destructor is deprecated.
Member function templates never suppress generation of special member functions.
Chapter 4 Smart Pointers
原生指针的几大“罪过”
不能说明它指向一个对象还是一个数组
当使用完毕时,不知道是否应该释放它(这个指针是否拥有内存资源的管理权)
如果要释放,不知道是用
delete,还是需要其他不同的释放方式?如果决定用
delete,是该用delete就可以(对象),还是delete [](数组)?代码太多时,正确找到每个应该释放的地方不太容易。忘记释放会导致内存泄漏,而多次释放会导致未定义的行为
不知道这个指针是否是一个悬空的指针(dangling pointer,指向一块不再拥有资源管理权的指针)
C++11中的4种指针
std::auto_ptrstd::unique_ptrstd::shared_ptrstd::weak_ptr
std::auto_ptr被std::unique_ptr所替代,除非要编译C++98的legacy code,否则就不再应该使用std::auto_ptr。
Item 18: Use std::unique_ptr for exclusive-ownership resource management
std::unique_ptr的特点和典型用法
通常认为,std::unique_ptr和原生指针占据同样大小的内存。
std::unique_ptr体现的是独占资源的语义。
移动一个std::unique_ptr,就是将其占据的资源管理权从source pointer转移到了destination pointer,并且同时source pointer被置为nullptr。
因为std::unique_ptr体现的是独占资源的语义,所以它不可复制(否则出现两个都占有同一资源的指针,并且都声称是独占,从而导致重复释放资源,会导致错误)。所以std::unique_ptr是move-only type。
一般默认delete是std::unique_ptr释放资源(原生指针)的操作。
典型的用法是,一个factory function,返回一个std::unique_ptr。
class Investment { /* ... */ };
class Stock: public Investment { /* ... */ };
class Bond: public Investment { /* ... */ };
class RealEstate: public Investment { /* ... */ };
template<typename... Ts> // return std::unique_ptr
std::unique_ptr<Investment> // to an object created
makeInvestment(Ts&&... params); // from the given args
// pInvestment is of type std::unique_ptr<Investment>
auto pInvestment = makeInvestment( arguments );
std::unique_ptr也可以用作容器元素。当它被move为容器元素,而容器又作为一个class的data member时,当这个class的object被销毁时,容器里的std::unique_ptr同样也会按照它初始化时设定的delete函数,来释放资源。
一般情况下,这个ownership chain如果被打断(比如early function return or break from a loop),std::unique_ptr所占用的资源也会被释放。
但也有一些例外,这些一般来自于程序的异常终止,比如,异常传播到线程主函数以外,违反了noexcept的声明,以及std::abort会exit function( std::_Exit, std::exit, or std::quick_exit)被调用时,都会导致std::unique_ptr所占用的资源无法被释放。
std::unique_ptr使用自定义的deleter
除了使用默认的delete操作符来在合适的时机释放原生指针所指向的内存资源,还可以使用定制化的deleter来代替delete操作符,这个deleter可以是函数,仿函数,以及lambda。
// custom deleter (a lambda expression)
auto delInvmt = [](Investment* pInvestment) {
makeLogEntry(pInvestment);
delete pInvestment;
};
// revised return type
template<typename... Ts>
std::unique_ptr<Investment, decltype(delInvmt)>
makeInvestment(Ts&&... params) {
// ptr to be returned
std::unique_ptr<Investment, decltype(delInvmt)> pInv(nullptr, delInvmt);
if ( /* a Stock object should be created */ ) {
pInv.reset(new Stock(std::forward<Ts>(params)...));
} else if ( /* a Bond object should be created */ ) {
pInv.reset(new Bond(std::forward<Ts>(params)...));
} else if ( /* a RealEstate object should be created */ ) {
pInv.reset(new RealEstate(std::forward<Ts>(params)...));
}
return pInv;
}
从上面的例子,可以有以下几点总结
使用lambda不仅方便,而且比传统的函数更有效
当使用custom deleter的时候,
std::unique_ptr的第二个模板参数就得是这个deleter的类型(这里使用decltype)当使用custom deleter的时候,初始化一个
std::unique_ptr对象的第一个参数是原生指针,第二个参数就得是这个custom deleterC++11不允许从原生指针到智能指针的隐式转换,所以需要使用
reset使用
std::forward的原因是为了保留参数的左值和右值属性custom deleter的参数是一个基类的指针,那么就要求基类的析构函数是虚函数
上面的例子,如果使用C++14,封装特征就可以变得更好
template<typename... Ts>
auto makeInvestment(Ts&&... params) {
auto delInvmt = [](Investment* pInvestment) {
makeLogEntry(pInvestment);
delete pInvestment;
};
// ptr to be returned
std::unique_ptr<Investment, decltype(delInvmt)> pInv(nullptr, delInvmt);
if ( /* a Stock object should be created */ ) {
pInv.reset(new Stock(std::forward<Ts>(params)...));
} else if ( /* a Bond object should be created */ ) {
pInv.reset(new Bond(std::forward<Ts>(params)...));
} else if ( /* a RealEstate object should be created */ ) {
pInv.reset(new RealEstate(std::forward<Ts>(params)...));
}
return pInv;
}
std::unique_ptr的大小问题
当deleter是默认的delete时,std::unique_ptr的大小和原生指针的大小是一样的。
当deleter是函数指针时,std::unique_ptr的大小一般会从一个word变到两个word。
当deleter是function object时,std::unique_ptr的大小变化要看这个函数的state。对于stateless function object(比如没有capture的lambda),大小就不会有什么变化。因此,如果deleter既可以是函数,又可以是captureless lambda expression的时候,使用lambda会更好。
当function object deleter有extensive state的时候,会导致std::unique_ptr大小有显著的增加,这时候就该考虑是否该修改当前的设计了。
// custom deleter, as stateless lambda
auto delInvmt1 = [](Investment* pInvestment) {
makeLogEntry(pInvestment);
delete pInvestment;
};
// return type has size of Investment*
template<typename... Ts>
std::unique_ptr<Investment, decltype(delInvmt1)>
makeInvestment(Ts&&... args);
// custom deleter as function
void delInvmt2(Investment* pInvestment) {
makeLogEntry(pInvestment);
delete pInvestment;
}
// return type has size of Investment* plus at least size of function pointer!
template<typename... Ts>
std::unique_ptr<Investment, void (*)(Investment*)>
makeInvestment(Ts&&... params);
std::unique_ptr的两种形式
std::unique_ptr有两种形式
std::unique_ptr<T>单个对象std::unique_ptr<T[]>数组
单个对象的形式,不会有索引[]操作符的重载,而数组形式,不会有解引用(operator*,operator->)操作符的重载。
Scott Meyers建议,不要使用std::unique_ptr<T[]>(std::unique_ptr的数组形式),因为std::array,std::vector和std::string等都是比它更好的使用方法。而唯一比较好的使用方式,是声明一个由C-API返回的的原生指针所指向堆内存的资源管理权。
std::unique_ptr可以很方便转换为std::shared_ptr
std::unique_ptr最吸引人的特点,就是它可以方便有效地(隐式)转换为一个std::shared_ptr。
// converts std::unique_ptr to std::shared_ptr
std::shared_ptr<Investment> sp = makeInvestment( arguments );
因为factory function不知道使用者更想使用std::unique_ptr还是一个std::shared_ptr,所以返回一个std::unique_ptr是最好的办法。
Things to Remember
std::unique_ptris a small, fast, move-only smart pointer for managing resources with exclusive-ownership semantics.By default, resource destruction takes place via delete, but custom deleters can be specified. Stateful deleters and function pointers as deleters increase the size of
std::unique_ptrobjects.Converting a std::unique_ptr to a
std::shared_ptris easy.
Item 19: Use std::shared_ptr for shared-ownership resource management
C++关于资源管理的需求:像Garbage collection一样自动工作的系统,适用于所有的资源,并且有可预测的释放时机。
std::shared_ptr是C++11给出的答案。
计数器的代价(performance implication)
std::shared_ptr是一个原生指针的两倍大小这是由于它包含两个指针:一个指向内存,一个指向reference count(STL的实现方式)
reference count实际上是一个字(word)
32-bit机器的字就是4字节,64-bit机器的字就是8字节。
指向reference count的指针,必须是动态分配的(dynamically allocated)
这是因为,reference count是要跟随所指向的对象,并依次记录其引用个数,但被引用的对象却对此一无所知,所以它们并没有用来存储reference count的地方,所以reference count的指针必须用动态分配的方式。这种动态分配方式的开销,可以通过
std::make_shared来避免,但有些情况下,std::make_shared不能使用。reference count的自增和自减操作,必须是原子操作(atomic)
这是为了防止多线程时出现问题(比如,一个线程正在做析构操作,而另一个线程正在拷贝那个同样被引用的对象)
为何构造函数不总是自增reference count?
std::shared_ptr的构造函数,通常 会自增reference count(std::shared_ptr constructors only usually increment the reference count for the object they point to)。
但有例外,例外就是移动构造(move construction)。因为移动构造时,旧指针会被重置为nullptr,而新指针会指向原先旧指针指向的object,因为reference count不会增加。
也因为这样,移动std::shared_ptr要比拷贝std::shared_ptr更快(move construction,move assignment)
std::shared_ptr的大小问题
如前所述,std::shared_ptr的包含两个指针,所以就是两个指针的大小。
但如果指定了自定义的deleter,实际上std::shared_ptr的大小也不会改变(哪怕这个deleter是一个function object)
原因其实是,前面提到的reference count的指针,实际上是一个指向control block的指针(如下图),它指向的是一块堆上的内存,而它包含有reference count,weak count,custom deleter,allocator等。所以,实际上,当使用自定义的deleter的时候,std::shared_ptr是使用了更多的内存。
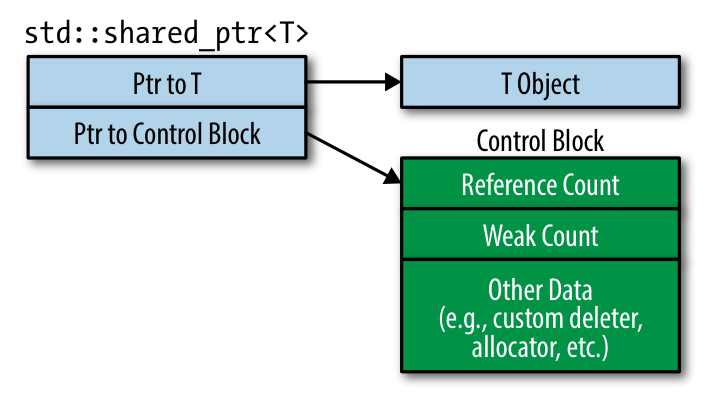
关于control block的rules
至少,我们希望control block是在创建第一个指向object的std::shared_ptr的时候创建的,但创建一个std::shared_ptr的时候,函数并不能知道是不是还有其他的std::shared_ptr引用了同样的对象。
所以,就只好使用以下的规则
std::make_shared总是创建一个control block。因为它会生成一个新的对象并指向它,所以在
std::make_shared调用的时候,这个新的对象没有control block。当使用unique-ownership的指针创建一个
std::shared_ptr的时候,创建一个control block。因为unique-ownership的指针没有control block,所以此时可以创建一个control block。
当使用原生指针(raw pointer)创建一个
std::shared_ptr的时候,创建一个control block。如果想用一个已经有control block的对象创建
std::shared_ptr,就应该传入std::shared_ptr或std::weak_ptr,而不应该使用原生指针(raw pointer)。
这也就是为什么使用同一个原生指针(raw pointer)来创建两个或多个std::shared_ptr时,会出现重复释放的问题。
原因就是多个control block被创建出来,因此就有多个reference count,因此也就会产生多次释放。
auto pw = new Widget; // pw is raw ptr
std::shared_ptr<Widget> spw1(pw, loggingDel); // create control block for *pw
std::shared_ptr<Widget> spw2(pw, loggingDel); // create 2nd control block for *pw!
所以,通常的写法是,把new出来的结果直接当做std::shared_ptr的初始化参数使用,然后再用生成好的std::shared_ptr去初始化其他的std::shared_ptr
std::shared_ptr<Widget> spw1(new Widget, loggingDel); // direct use of new
std::shared_ptr<Widget> spw2(spw1); // spw2 uses same control block as spw1
使用enable_shared_from_this以及前提条件
使用
std::enable_shared_from_this定义了一个成员函数:shared_from_this()。
当继承了std::enable_shared_from_this的子类里面的成员函数,想要获得一个指向当前*this的shared_ptr时, 这个成员函数shared_from_this(),就可以派上用场。
void Widget::process() {
// as before, process the Widget
// add std::shared_ptr to current object to processedWidgets
processedWidgets.emplace_back(shared_from_this());
}
shared_from_this()会搜索当前对象(*this)的control block,然后创建一个新的shared_ptr指向它,并且”引用“这个已经存在的control block(即,没有创建新的control block)
前提条件
所以,能够在子类的成员函数里面使用shared_from_this()有个前提条件:必须已经有一个存在的shared_ptr指向当前的*this(比如,在成员函数外面调用shared_from_this()),否则会发生未定义的行为(通常shared_from_this()会抛异常)
避免异常的通常做法
通常的做法是,使用一个public的static factory function来创建一个std::shared_ptr,并且,把构造函数声明为private。
class Widget: public std::enable_shared_from_this<Widget> {
public:
// factory function that perfect-forwards args to a private ctor
template<typename... Ts>
static std::shared_ptr<Widget> create(Ts&&... params);
void process(); // as before
private:
// ctors
/* ... */
};
何时使用std::shared_ptr ?
Scott Meyers还提到,control block的实现比通常想的要更复杂。它用到了继承,甚至有virtual function机制(保证指向的对象最后会被合理销毁)。他列举了以下可能的cost
dynamically allocated control blocks
arbitrarily large deleters
allocators
virtual function machinery
atomic reference count manipulations
这些都会导致shared_ptr的性能受到影响,但瑕不掩瑜,通常情况下这些cost是合理的,
通常使用
std::make_shared,control block只有3个word的大小解引用
shared_ptr的开销基本就是解引用一个原生指针Dereferencing a
std::shared_ptris no more expensive than dereferencing a raw pointer.reference count的自增和自减操作,通常是一到两个原子操作(通常映射为一条机器指令)
虚函数机制通常只有在一个object被销毁时才用到
所以,付出这些代价是划算的。
所以,通常在怀疑是否应该使用shared ownership的生命周期跟踪时,应当考虑一下是否该使用std::unique_ptr,而不是std::shared_ptr。而且通常std::unique_ptr可以很容易地转换成一个std::shared_ptr。
std::shared_ptr 和std::unique_ptr不同,它不能指向一个数组,即没有std::shared_ptr<T[]>这样的东西,它只能指向一个single object。
Things to Remember
std::shared_ptrs offer convenience approaching that of garbage collection for the shared lifetime management of arbitrary resources.Compared to
std::unique_ptr,std::shared_ptrobjects are typically twice as big, incur overhead for control blocks, and require atomic reference count manipulations.Default resource destruction is via delete, but custom deleters are supported. The type of the deleter has no effect on the type of the
std::shared_ptr.Avoid creating
std::shared_ptrs from variables of raw pointer type.
Item 20: Use std::weak_ptr for std::shared_ptr-like pointers that can dangle
为何有std::weak_ptr
对于std::shared_ptr,有可能它指向一个对象的时候,这个对象已经被销毁了,但std::shared_ptr并不会知道。这时候就产生一个所谓的 dangle 的指针。
std::weak_ptr就是用来处理这样的问题,它使用起来像std::shared_ptr,但它不参与管理它所指向对象的ownership,即,不改变reference count。
std::weak_ptr既不能解引用,也不能用来测试是否为空(null),这是由于它并不是一个独立的智能指针,它实际上是std::shared_ptr的一个扩展(augmentation)
如何创建std::weak_ptr
通常,一个std::weak_ptr是以一个std::shared_ptr为初始化参数构造的。
// after spw is constructed, the pointed-to Widget's ref count (RC) is 1
auto spw = std::make_shared<Widget>();
// wpw points to same Widget as spw. RC remains 1
std::weak_ptr<Widget> wpw(spw);
// RC goes to 0, and the Widget is destroyed. wpw now dangles
spw = nullptr;
// if wpw doesn't point, to an object
if (wpw.expired()) { /* ... */ }
正如上面所示,std::weak_ptr可以用来测试它指向的对象是否以及失效(销毁)。
std::weak_ptr 到底有什么用的例子
factory method cache
设想有个factory函数loadWidget,它的作用是通过一个ID,返回一个对象(std::unique_ptr),这个操作很耗时(比如文件操作或I/O操作)。
std::unique_ptr<const Widget> loadWidget(WidgetID id);
那么优化的一个办法是,把返回的Widget的这些对象(std::unique_ptr)都缓存起来。
但这样潜在的问题是,把所有的对象缓存起来的话,数量太多可能引起性能问题。
所以,更好的办法是,如果缓存的对象如果不再使用,那么就可以销毁它。
这样的话,调用者就得接收一个指向这个cache object的智能指针,并且调用者也得知道这些cache object的生命周期,而且,这些cache object也需要一个(智能)指针。
此时,std::weak_ptr就派上用场。
因为std::weak_ptr当做指向这些cache object的指针,就可以知道这些object什么时候被销毁了(生命周期),而且,此时factory函数要返回的就应该是一个std::shared_ptr,因为这样它才会被调用者拿去使用,并且在合适的时机销毁,之后那些cache object的指针就可以通过expired来检查对应的object是否已经释放。
下面是一个简单粗暴的cache实现
std::shared_ptr<const Widget> fastLoadWidget(WidgetID id) {
static std::unordered_map<WidgetID, std::weak_ptr<const Widget>> cache;
// objPtr is std::shared_ptr to cached object (or null if object's not in cache)
auto objPtr = cache[id].lock();
if (!objPtr) { // if not in cache,
objPtr = loadWidget(id); // load it
cache[id] = objPtr; // cache it
}
return objPtr;
}
the Observer design pattern
观察者模式中,有subject和observer
subject,objects whose state may change,即状态会改变的对象
observer,objects to be notified when state changes occur,即当subjects发生状态改变时,被通知的对象
在这种模式下,每个subject通常都包含有一个或多个指向observer的指针,以便自身状态发生变化的时候,调用observer(的函数)来通知观察者。
那么,这时候就可以使用std::weak_ptr,以便在调用observer的函数之前,查看observer是否还有效。
Resolve circular dependency
另外一个应用,是可以解决std::shared_ptr的循环引用导致的内存泄漏问题。
假如有两个对象A和C各自有一个std::shared_ptr 指向同一个object B,现在假如B也需要一个指针指向A,那么这个指针应该是raw pointer,std::shared_ptr还是std::weak_ptr?
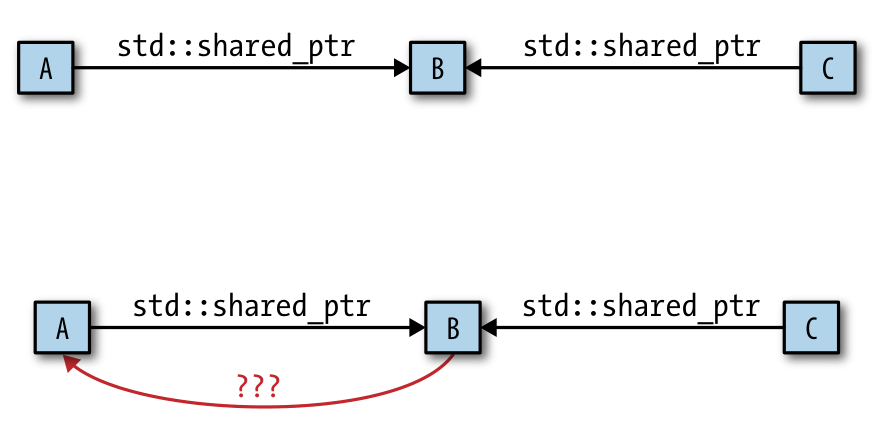
如果是原生指针
这个的问题在于,如果A被销毁之后,B指向A的指针就变成了一个dangling pointer,并且B没有办法知道这时候它已经变成了一个dangling pointer
如果是
std::shared_ptr这个的问题在于,产生循环引用之后,无法释放资源导致内存泄漏。哪怕再没有其他指针指向B,但A和B各自的指针会使得reference count始终不能减少,最终导致无法释放。
如果是
std::weak_ptr此时,
std::weak_ptr是最佳选择,而且可以避免上面两种问题。如果A已经被释放,那么B可以通过
std::weak_ptr的expired函数得知A已经被销毁。而且,虽然A和B都有一个指针相互引用,但B指向A的
std::weak_ptr并不会增加指向A的reference count(即如果没有其他指针指向A的话,A的reference count,实际上是0),所以就不会阻止A被释放。
std::weak_ptr的使用注意
通常,一个hierarchical的结构,比如tree,它的child node通常只被它的parent node所有,即当parent被destroyed的时候,child同样也应该被destroy。
那么,通常从parent到child的指针可以是std::unique_ptr,而从child到parent的指针可以是raw pointer。
虽然std::weak_ptr不影响reference count,但它和std::shared_ptr类似,也有一个对应的control block,而且实际上它有一个second reference count。更多内容在item 21。
Things to Remember
Use
std::weak_ptrforstd::shared_ptr-like pointers that can dangle.Potential use cases for
std::weak_ptrinclude caching, observer lists, and the prevention ofstd::shared_ptrcycles.
Item 22: When using the Pimpl Idiom, define special member functions in the implementation file.
什么是PImpl Idiom?
PImpl Idiom = Pointer IMPLementation Idiom
简而言之,就是把class里面的data members,从原先的主类(在头文件中)里面,转移到一个辅助类(在对应的源文件中)里面,然后再在原先的主类里面添加一个指向这个辅助类的指针。
这样做的好处是什么?
因为这些data member可能是各种不同类型的对象,所以要include它们对应的头文件。如果它们的头文件被修改了,那么在编译的时候,那么引用了这些头文件的,以及间接引用了这些头文件的头文件,都需要重新编译,从而导致编译时间增加(excessive compilation time)。
如果把这些data member发到源文件中去,那么主类的头文件就可以不再引用这些data member对应的头文件了(因为使用了指向辅助类的一个指针),而由源文件去引用这些头文件。这样避免了主类所在的头文件被其他文件引用时,那些data member头文件变化而引起的编译时间增加。
下面是Scott Meyers给出的一个例子。
在没有使用PImpl Idiom之前的Widget类
/* in header "widget.h" */
class Widget {
public:
Widget();
private:
std::string name;
std::vector<double> data;
Gadget g1, g2, g3; // Gadget is some user-defined type
};
使用了PImpl Idiom之后的Widget类(注意,在头文件中声明了一个private的类中类,并且有一个析构函数来释放指针所指向的object)
/* in header "widget.h" */
class Widget {
public:
Widget();
~Widget(); // dtor is needed—see below
private:
struct Impl; // declare implementation struct and pointer to it
Impl *pImpl;
};
/* in impl. file "widget.cpp" */
#include "widget.h"
#include "gadget.h"
#include <string>
#include <vector>
// definition of Widget::Impl with data members formerly in Widget
struct Widget::Impl {
std::string name;
std::vector<double> data;
Gadget g1, g2, g3;
};
// allocate data members for this Widget object
Widget::Widget() : pImpl(new Impl) {}
// destroy data members for this object
Widget::~Widget() { delete pImpl; }
在PImpl Idiom中使用std::unqiue_ptr
根据前面的内容,显而易见,当使用PImpl Idiom时需要一个raw pointer,而这个raw pointer正好是可以使用std::unqiue_ptr来代替的地方。
下面是使用std::unqiue_ptr来代替原先raw pointer的代码。
/* in header "widget.h" */
class Widget {
public:
Widget();
private:
struct Impl; // declare implementation struct and pointer to it
Impl *pImpl; // use smart pointer instead of raw pointer
};
/* in impl. file "widget.cpp" */
#include "widget.h"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // as before
std::string name;
std::vector<double> data;
Gadget g1, g2, g3;
};
// per Item 21, create std::unique_ptr via std::make_unique
Widget::Widget() : pImpl(std::make_unique<Impl>()) {}
可以看到,使用了std::unqiue_ptr之后,原先Widget的析构函数就不需要了,因为std::unqiue_ptr会自己管理并释放所指的对象。
但是,虽然它可以编译通过,可使用它(Widget)的代码却会编译失败。
下面是一种最简单的使用方式,但编译会失败
#include "widget.h"
Widget w; // error!!
失败的原因是什么?
因为此时没有显示地给Wdiget写出析构函数,所以编译器会帮忙生成default destructor,并且在其中调用std::unqiue_ptr的析构函数,而std::unqiue_ptr的default deleter会使用delete来释放内存(即delete std::unqiue_ptr中所包含的raw pointer)。
但在通常的default deleter实现中,在delete之前,通常会使用static_assert来确保这个raw pointer不是指向 incomplete type。因为编译器生成的special member function通常都是inline(在头文件中),所以这个指针所指向辅助类的实现,因为在源文件而不在头文件中,所以是 incomplete type,从而导致编译失败。
为了使编译通过,就需要在析构的时候,使得这个辅助类的实现对编译器可见。
所以,就在头文件中声明析构函数,并在源文件中实现这个析构函数,修改如下。
/* in header "widget.h" */
class Widget {
public:
Widget();
~Widget(); // Define it in CPP file!
private:
struct Impl; // declare implementation struct and pointer to it
Impl *pImpl; // use smart pointer instead of raw pointer
};
/* in impl. file "widget.cpp" */
#include "widget.h"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // as before
std::string name;
std::vector<double> data;
Gadget g1, g2, g3;
};
// per Item 21, create std::unique_ptr via std::make_unique
Widget::Widget() : pImpl(std::make_unique<Impl>()) {}
// ~Widget definition
Widget::~Widget() {}
或者,在源文件中直接使用Widget::~Widget() = default,也可以使得编译器将实现放在源文件中。
PImpl Idiom中的copy和move constructor以及assignment
Move constructor和move assignment
因为PImpl Idiom中的主类含有一个指针(std::unqiue_ptr),所以它很适合用来实现移动语义。
和之前讨论同样的原因,std::unique_ptr的赋值操作,会调用default deleter,而它需要在使用delete之前,使用static_assert来确保所指向的类型不是一个incomplete type,而因为编译器生成的special function都是inline,所以client code使用时,会产生编译错误。
解决的办法和之前一样,在头文件中声明,然后在源文件中实现定义即可。
Copy constructor和copy assignment
同样是因为PImpl Idiom中的主类含有一个指针,所以它的拷贝构造和拷贝赋值就是值得注意的地方。
如果主类中的是raw pointer,那么编译器生成的拷贝构造和拷贝赋值实际上是浅拷贝(shallow copy)
如果主类中的是std::unique_ptr,那么编译器生成的拷贝构造和拷贝赋值,按照std::unique_ptr的特性,在赋值时就会发生资源管理权的转移,变成事实上的移动构造和移动拷贝。
所以,如果需要深拷贝(deep copy),就需要自己手动实现。
和前面的析构函数、移动构造和移动赋值类似,也需要将拷贝构造和拷贝赋值在头文件中声明,并在源文件中实现其定义。
综上,在PImpl Idiom中实现了析构函数,移动构造,移动赋值,拷贝构造,拷贝赋值的代码如下。(需要注意的是,copy assignment用到了编译器给Impl生成的copy operator重载函数。
/* in header "widget.h" */
class Widget {
public:
Widget();
// Declare dtro in header, but definition should be in cpp file
~Widget();
// Declare move-ctor & move-assignment in header, but define them in cpp file
Widget(const Widget& rhs);
Widget& operator=(const Widget& rhs);
// Delcare copy-ctor ^ copy assignment in header, but define them in cpp file
Widget(const Widget& rhs);
Widget& operator=(const Widget& rhs);
private:
struct Impl; // declare implementation struct and pointer to it
Impl *pImpl; // use smart pointer instead of raw pointer
};
/* in impl. file "widget.cpp" */
#include "widget.h"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // as before
std::string name;
std::vector<double> data;
Gadget g1, g2, g3;
};
// per Item 21, create std::unique_ptr via std::make_unique
Widget::Widget() : pImpl(std::make_unique<Impl>()) {}
// ~Widget definition
Widget::~Widget() = default;
// Move-ctor & move assignment definitions
Widget::Widget(Widget&& rhs) = default;
Widget& Widget::operator=(Widget&& rhs) = default;
// Copy ctor & copy operator=
Widget::Widget(const Widget& rhs) : pImpl(std::make_unique<Impl>(*rhs.pImpl)) {}
Widget& Widget::operator=(const Widget& rhs) { *pImpl = *rhs.pImpl; return *this; }
Things to Remember
The Pimpl Idiom decreases build times by reducing compilation dependencies between class clients and class implementations.
For
std::unique_ptrpImpl pointers, declare special member functions in the class header, but implement them in the implementation file. Do this even if the default function implementations are acceptable.The above advice applies to
std::unique_ptr, but not tostd::shared_ptr.
Chapter 5 Rvalue References, Move Semantics, and Perfect Forwarding
Move semantics,perfect forwarding和rvalue references
Move semantics(移动语义)
使得编译器能够以更廉价的办法用移动代替复制
移动语义可以生成只能移动的类型:
std::unique_ptr,std::future,std::threadPerfect forwarding(完美转发)
在function template中,可以完美转发参数
Rvalue references(右值引用)
右值引用是连接移动语义和完美转发的纽带,正是右值引用使得它们成为可能。
这三者实际上比它表面上看起来更微妙
std::move实际上不是什么都能移动完美转发实际上也不完美
移动操作有时候并不比复制更快(当确实更快时,实际上没有你想象的那么快)
移动操作有时候用在移动不合法(valid)的地方
type&&并不总是代表右值引用
本章中,需要注意的是,一个参数永远是左值,哪怕它的类型是右值引用。
比如下面的w参数,它是一个左值,但它的类型的确是一个右值引用。
void f(Widget&& w);
Item 23: Understand std::move and std::forward
移动其实是转换
std::move不是什么都能移动,std::forward也不是什么都能转发,它们在运行时(runtime)不做任何事情,因为它们不产生任何可执行的代码,一个字节也不产生。
std::move和std::forward都是函数(通常是function template),实现的是转换功能(cast)
std::move无条件地把参数转换为rvaluestd::forward只有当条件满足的时候才执行转换
C++11中std::move的一种实现
template<typename T> // in namespace std
typename remove_reference<T>::type&&
move(T&& param) {
using ReturnType = typename remove_reference<T>::type&&; // alias declaration;
return static_cast<ReturnType>(param);
}
C++14中std::move的一种实现
template<typename T> // C++14; still in namespace std
decltype(auto) move(T&& param) {
using ReturnType = remove_reference_t<T>&&;
return static_cast<ReturnType>(param);
}
所以,从实现可以看到,std::move其实更应该叫做rvalue_cast,它只做转换(cast),不做真正的移动(move)。
一个没有移动的例子
假如有下面的class Annotation,它有一个构造函数接收一个const std::string参数,然后使用了std::move,但实际上,text并没有被“移动”到data member中去。
class Annotation {
public:
explicit Annotation(const std::string text)
: value(std::move(text)) // "move" text into value; this code
{ /* ...*/ } // doesn't do what it seems to!
private:
std::string value;
};
这是由于参数text是const std::string,而当它被传入std::move之前,它是一个lvalue的const std::string,当它从std::move返回之后,它是一个rvalue的const std::string。(不影响const-ness)。
而std::string如下,它有一个接收常量左值引用和一个接收右值引用的构造函数。实际上,前面的rvalue的const std::string会被下面的拷贝构造函数所接收(因为右值或常量右值可以绑定到常量左值引用上去,而常量右值不能绑定到右值引用上去)
// std::string is actually a typedef for std::basic_string<char>
class string {
public:
string(const string& rhs); // copy ctor
string(string&& rhs); // move ctor
};
从这个例子可以看到
如果想使用移动语义,就不能把一个对象声明为常量(
const),否则会默认转换为拷贝std::move除了不能转换有些对象外,也不能保证转换之后的对象能够被移动
一个满足条件才转发的例子
下面的一个例子中,process函数有对lvalue和rvalue的重载。在logAndProcess函数中,我们期望传入的参数param如果是lvalue,就调用process的lvalue重载,如果param如果是rvalue,就调用process的rvalue重载。
但是,像所有的函数参数一样,param是左值,所以我们希望,只有当param是被右值初始化的时候,能把它的右值属性保留并转发给process函数,这就是std::forward所做的事情。
所以对于std::forward,只有当参数被右值初始化时,才把它转换为一个右值
it casts to an rvalue only if its argument was initialized with an rvalue.
void process(const Widget& lvalArg); // process lvalues
void process(Widget&& rvalArg); // process rvalues
template<typename T> // template that passes param to process
void logAndProcess(T&& param) {
auto now = std::chrono::system_clock::now(); // get current time
makeLogEntry("Calling 'process'", now);
process(std::forward<T>(param));
}
Widget w;
logAndProcess(w); // call with lvalue
logAndProcess(std::move(w)); // call with rvalue
都是转换为lvalue,为什么需要这两个函数?
从前面的分析可以看到,实际上std::move和std::forward都完成了转换为右值的功能,只是std::move是无条件的转换,而std::forward是满足了条件之后才转换。
所以理论上可以只用std::forward而不用std::move(还没太想明白)。
(2022-10-31,想明白了…他的意思是,因为需要一个右值,所以才使用std::move,否则不用,那这就是std::forward所做的事情,所以理论上可以只用std::forward而不用std::move)
但std::move的好处是,它更方便,能减少出错的机会,并且说明更加清楚。
std::move’s attractions are convenience, reduced likelihood of error, and greater clarity.
下面是分别使用std::move和std::forward的一个例子(统计移动构造的次数)。
显然可以看到std::move只需要一个函数参数,而std::forward除了函数参数外,还需要一个模板参数,并且这个参数得正确,否则可能最后得到就不是拷贝构造了。
class Widget {
public:
Widget(Widget&& rhs) : s(std::move(rhs.s)) { ++moveCtorCalls; }
private:
static std::size_t moveCtorCalls;
std::string s;
};
class Widget {
public:
Widget(Widget&& rhs) : s(std::forward<std::string>(rhs.s)) { ++moveCtorCalls; }
private:
static std::size_t moveCtorCalls;
std::string s;
};
Things to Remember
std::moveperforms an unconditional cast to an rvalue. In and of itself, it doesn’t move anything.
std::forwardcasts its argument to an rvalue only if that argument is bound to an rvalue.Neither
std::movenorstd::forwarddo anything at runtime.
Item 24: Distinguish universal references from rvalue references.
T&&不只是右值引用
正如所述,T&&不仅指代右值引用,它还是万能引用(universal reference)
下面几个例子既有T&&表示右值引用,又有T&&表示可能是右值引用又可能表示左值引用(万能引用)
void f(Widget&& param); // rvalue reference
Widget&& var1 = Widget(); // rvalue reference
auto&& var2 = var1; // not rvalue reference
template<typename T>
void f(std::vector<T>&& param); // rvalue reference
template<typename T>
void f(T&& param); // not rvalue reference
当T&&表示万能引用(universal reference)的时候
它既可以绑定到左值(lvalue),也可以绑定到右值(rvalue)
它可以绑定到常量(
const),也可以绑定到非常量(non-const)它可以绑定到易变量(
volatile),也可以绑定到非易变量(non-volatile)
万能引用T&&出现的地方
当T&&表示万能引用的时候,一般出现在如下的上下文中
函数模板参数(function template parameters),这种最常见
auto关键字声明
这两种上下文的共同点时,出现了类型推导(type deduction)。下面是这两种情况的例子。
template<typename T>
void f(T&& param); // param is a universal reference
auto&& var2 = var1; // var2 is a universal reference
万能引用仍然是引用,所以它必须被初始化。而由左值或右值来初始化,就决定了万能引用是左值引用还是右值引用。
左值初始化万能引用,万能引用绑定到左值,即万能引用就是左值引用
右值初始化万能引用,万能引用绑定到右值,即万能引用就是右值引用
函数模板中的万能引用是由传入的参数的左值或右值性所决定的。
template<typename T>
void f(T&& param); // param is a universal reference
Widget w;
f(w); // lvalue passed to f; param's type is Widget& (i.e., an lvalue reference)
f(std::move(w)); // rvalue passed to f;
//param's type is Widget&& (i.e., an rvalue reference)
T&&是万能引用的条件
万能引用的必须有两个条件
发生类型推导
形式必须是
T&&
所以发生了类型推导,只是万能引用的必要条件,两者必须同时满足才是万能引用。
需要注意的是,T可以是其他名字表示类型。
下面的例子说明了发生了类型推导,但形式不是T&&,所以就不是万能引用。
template<typename T> // not form of "T&&", so it isn't uninversal ref
void f(std::vector<T>&& param); // param is an rvalue reference
template<typename T> // not form of "T&&", so it isn't uninversal ref
void f(const T&& param); // param is an rvalue reference
下面的例子说明了看似发生了类型推导,但是实际上不是类型推导的例子
template<class T, class Allocator = allocator<T>> // from C++ Standards
class vector {
public:
void push_back(T&& x);
template <class... Args>
void emplace_back(Args&&... args);
/* ... */
};
对于push_back,这个看似有类型推导,但实际不是的原因是:push_back是某种类型T的实例化之后的vector的member function,它不能脱离这个实例化的vector而单独存在。一旦实例化之后,push_back的参数就是一个确定的右值引用,而不是万能引用了。
比如std::vector<Widget> w;,那么成员函数就变成了void push_back(Widget &&x)了。
对于emplace_back,它就是万能引用。原因是,它的类型参数不受某个特定实例化之后的vector的影响,而且参数形式就是T&&(只是用了不同的名字Args)。
比如std::vector<Widget> w;,成员函数仍然是template <class... Args> void emplace_back(Args&&... args),显然这里仍然会发生类型推导。
当然,其实对于emplace_back,它的参数实际上是parameter pack,不是一个type parameter。这里为了讨论方便,仍然把它当做a type parameter。
auto&&是万能引用
Scott Meyers举例说明了auto&&作为万能引用在lambda中是使用。
// C++14
auto timeFuncInvocation = [](auto&& func, auto&&... params) {
// start timer;
std::forward<decltype(func)>(func)( // invoke func
std::forward<decltype(params)>(params)... // on params
);
// stop timer and record elapsed time;
};
上面的是一个记录函数运行时间的lambda,它的参数有两个,第一个是auto&& func,正如前面所述,这是一个万能引用(绑定到一个lvalue,rvalue或着一个可调用的对象);第二个是auto&&... params,它是指代一个或者多个万能引用(universal reference parameter pack),即它能绑定到任意数量的类型对象上。
Things to Remember
If a function template parameter has type
T&&for a deduced type T, or if an object is declared usingauto&&, the parameter or object is a universal reference.If the form of the type declaration isn’t precisely
type&&, or if type deduction does not occur,type&&denotes an rvalue reference.Universal references correspond to rvalue references if they’re initialized with rvalues. They correspond to lvalue references if they’re initialized with lvalues.
Item 25: Use std::move on rvalue references, std::forward on universal references.
使用std::move和std::forward的场景
如果一个parameter是右值引用,那么我们就知道它所绑定的对象可以被移动,从而我们可以使用std::move来无条件地把它(或它的成员)转换为右值引用,以便移动给其他对象。
class Widget {
public:
// rhs is rvalue reference
Widget(Widget&& rhs) : name(std::move(rhs.name)), p(std::move(rhs.p)) { /* ... */ }
private:
std::string name;
std::shared_ptr<SomeDataStructure> p;
};
上面的rhs被设定为右值引用,所以我们知道我们可以把它移动给其他的对象。
rhs.name是一个具名变量,它是一个左值,所以如果我们要用它来移动初始化this->name的话,我们就需要使用std::move。rhs.p也是同理。
如果一个parameter是万能引用,那么我们知道,它既可能是右值引用,也可能是左值引用。所以,如果我们如果想利用它的右值性的话,就需要只有在它是右值的时候,才能使用。这就是std::forward发挥作用的地方。
class Widget {
public:
template<typename T>
// newName is universal reference
void setName(T&& newName) { name = std::forward<T>(newName); }
};
声明的T&&显然是一个万能引用,而newName它本身是一个具名变量,所以他是一个左值。
所以,如果想保留它的左值属性(lvalueness)或右值属性(rvalueness)的话,就需要使用std::forward,这样它是左值的时候,就不会转换成右值,仍然保留左值属性;如果是右值的时候,就将newName转换为右值,一样保留其右值属性。
这里是再次强调了std::move和std::forward的使用场景:如果本身就是右值引用,就应该用std::move无条件地将参数转换为右值;而如果是万能引用,就需要用std::forward有条件地(是右值引用的时候)将参数才将其转换为右值。
避免给右值引用使用std::forward
此外,给本身就是右值引用的参数使用std::forward并不是不行,但是这样做就是冗余,易错并且不符合习惯,所以应该避免。
避免给万能引用使用std::move
类似地,给对万能引用使用std::move,可能会造成意想不到的后果(比如修改了左值)。
下面的例子说明了给万能引用使用std::move的危害。
class Widget {
public:
// universal reference compiles, but is bad, bad, bad!
template<typename T>
void setName(T&& newName) { name = std::move(newName); }
/* ... */
private:
std::string name;
std::shared_ptr<SomeDataStructure> p;
};
std::string getWidgetName(); // factory function declarition
Widget w;
auto n = getWidgetName(); // n is local variable
w.setName(n); // moves n into w!
/* ... */ // n's value now unknown
避免使用多个重载函数来代替万能引用
原因有二
代码变多,没有这样用的习惯
有潜在的性能下降问题
最重要的是,设计的扩展性变差(模板的变长参数)
Scott Meyers举例说明了,使用两个重载函数来代替上面的万能引用版的setName,并不是一个好主意。
class Widget {
public:
// set from const lvalue
void setName(const std::string& newName) { name = newName; }
// set from rvalue
void setName(std::string&& newName) { name = std::move(newName); }
/* ... */
};
第一个原因是,现在就变成了需要同时维护两个函数(代码变多)
第二个原因是,性能也许变差了。
变差的原因是,如果有一个调用w.setName("Adela Novak")
如果是万能引用版的函数,那么就会保留
Adela Novak的左值属性,并直接通过std::string的重载函数operator=(const char *)进行赋值如果是使用两个重载函数的版本,首先
Adela Novak是const char *而不是std::string,所以它首先会通过这个Adela Novak构造一个临时的std::string,然后调用setName(std::string &&newName)的重载函数(因为临时变量是右值),然后通过std::string的move assignment进行移动赋值,最后销毁这个临时生成的变量std::string。
由此可见,有潜在的性能下降问题。
关于没有办法使用多个重载函数给lvalue和rvalue的参数的情况,函数模板的变长参数就是典型的例子。
Scott Meyers以std::make_shared和std::make_unique为例说明了,在这个问题上,万能引用是唯一的办法。
template<class T, class... Args> // from C++11 Standard
shared_ptr<T> make_shared(Args&&... args);
template<class T, class... Args> // from C++14 Standard
unique_ptr<T> make_unique(Args&&... args);
如果在一个函数里面,想要多次使用传入的右值引用或万能引用(但又只想在最后一次使用的时候发生移动操作),怎么办?
答案就是,只在最后一次使用的时候,使用std::move(给右值引用)或std::forward(给左值引用)。
Scott Meyers举了个多次使用万能引用的例子。
template<typename T>
void setSignText(T&& text) { // text is univ. reference
sign.setText(text); // use text, but don't modify it
auto now = std::chrono::system_clock::now(); // get current time
signHistory.add(now, std::forward<T>(text)); // conditionally cast text to rvalue
}
何时在函数返回的时候,使用std::move或std::forward
简单而言,
是值传递的方式返回(return-by-value)
返回的是一个右值引用或万能引用的传入参数
// Version 1, use std::move
Matrix operator+(Matrix&& lhs, const Matrix& rhs) { // by-value return
lhs += rhs;
return std::move(lhs); // move lhs into return value
}
// Version 2, just return itself
Matrix operator+(Matrix&& lhs, const Matrix& rhs) { // as above
lhs += rhs;
return lhs; // copy lhs into return value
}
在上面的第一个版本中,lhs是传入参数并且是一个右值引用,它本身是个左值,所以可以使用std::move把lhs的值移动到函数的返回值的地址上去。
第二个版本中,因为返回的是lhs本身,而它本身是个左值,所以它会迫使编译器把它拷贝到函数返回值的地址上去。
所以,如果Matrix支持移动操作的话,第一个版本是更高效的。哪怕Matrix不支持移动操作,它也会使用拷贝构造来进行拷贝,所以并不会出问题,况且如果之后支持了移动操作,也不需要进行任何修改就可以得到移动操作的加成。
template<typename T>
Fraction reduceAndCopy(T&& frac) { // by-value return universal reference param
frac.reduce();
return std::forward<T>(frac); // move rvalue into return value, copy lvalue
}
何时在函数返回的时候,不 使用std::move或std::forward:RVO(Return Value Optimization)
RVO = Return Value Optimization(sometimes refer to unnamed RVO)
NRVO = Named Return Value Optimization
copy elision
在函数里面返回局部变量(local object)的时候,不要对返回值使用std::move或std::forward,这是由于C++标准委员会(C++ Standardization Committee)很早的时候就考虑到了这一点,并且支持编译器进行优化,使得能够不需要拷贝(或移动)这个局部变量到返回值的地址上,而是直接在返回值的地址上构造它。
如果编译器选择不做这项优化(copy elision),那么C++标准要求它必须给返回值使用std::move(即这时候返回值必须被当做rvalue来对待)。
这个优化就是RVO。有时候为了区别返回的是一个临时变量还是具名的局部变量,用NRVO表示返回的是具名的局部变量,而RVO就直接表示临时变量的返回值优化。
这样的优化操作,也叫做copy elision(省略拷贝)。这样在返回地址上直接进行构造,要比拷贝或移动更有效。
但RVO也有条件,只有以下两个条件满足的时候,编译器才可以省略拷贝或者移动操作。
局部变量的类型和返回值的类型相同
返回的就是这个局部变量
this particular blessing says that compilers may elide the copying (or moving) of a local object in a function that returns by value if
(1) the type of the local object is the same as that returned by the function and
(2) the local object is what’s being returned.
下面的例子就是RVO的一个例子
Widget makeWidget() { // "Copying" version of makeWidget
Widget w;
/* ... */
return w; // "copy" w into return value
}
而下面的例子实际上阻止了RVO。原因是上面的第二个条件没有满足,因为返回的是一个rvalue reference,而不是局部变量本身了。
Widget makeWidget() { // "Move" version of makeWidget
Widget w;
/* ... */
return std::move(w); ; // move w into return value (don't do this!!!)
}
RVO是一项编译器优化,这意味着编译器可以选择不优化。但如果编译器不做这项优化,那么我们手动加上std::move也是应该避免的。
前面也提到了,这是因为C++标准要求,要么有copy elision的优化,要么隐式地在返回值上使用std::move。
所以,这时候,我们也应该避免自己加上std::move。
甚至,如果函数参数和返回值相同的时候,尽管不适用copy elision(因为不是局部变量?),但编译器也必须把返回值按照rvalue来处理(隐式使用std::move)
Widget makeWidget(Widget w) { // by-value parameter of same type as function's return
/* ... */
return w;
}
这时候,编译器就会处理成好像写成下面这样的形式(右值引用)。
Widget makeWidget(Widget w) { // by-value parameter of same type as function's return
/* ... */
return std::move(w); // treat w as rvalue
}
Things to Remember
Apply
std::moveto rvalue references andstd::forwardto universal references the last time each is used.Do the same thing for rvalue references and universal references being returned from functions that return by value.
Never apply
std::moveorstd::forwardto local objects if they would otherwise be eligible for the return value optimization.
Item 26: Avoid overloading on universal references.
本节Scott Meyers主要通过举例,说明了重载带有万能引用参数的函数非常容易出错,因此应该避免这样做。
使用万能引用对一个函数的优化
假如有个最初版本的函数logAndAdd,有三种调用。
std::multiset<std::string> names; // global data structure
void logAndAdd(const std::string& name) {
auto now = std::chrono::system_clock::now(); // get current time
log(now, "logAndAdd"); // make log entry
names.emplace(name); // add name to global data structure
}
// Calls in different ways
std::string petName("Darla");
logAndAdd(petName); // (1) pass lvalue std::string
logAndAdd(std::string("Persephone")); // (2) pass rvalue std::string
logAndAdd("Patty Dog"); // (3) pass string literal
第一种调用,petName是一个左值(lvalue),因为函数参数是常量左值引用,所以它最后会被直接传递到names.emplace(name),而因为petName是一个左值,所以无法避免拷贝,因此最终petName会被拷贝到names中去。
第二种调用,函数实参是一个临时构造的临时变量,因为函数参数是常量左值引用,所以同样地,它最后会被直接传递到names.emplace(name),而同样的形式参数name它本身是一个左值,所以它仍然会被拷贝到最终的names中去,但由于实参实际上是一个右值,所以这样的拷贝可以通过移动来避免,这是可以优化的地方。
第三种调用,因为函数的实参是const char *,所以函数调用时,会通过const char *隐式地创建一个临时变量std::string,显然这个临时变量是个右值。剩下的步骤和第二种调用类似。但实际上,std::string::emplace可以通过常量字符串(string literal,即const char *直接在std::multiset上构造新的std::string,所以这是这种调用方式可以优化的地方。
综上所述,那么可以使用一个万能引用来实现对后面两种调用的优化。
std::multiset<std::string> names; // global data structure
template<typename T>
void logAndAdd(T&& name) {
auto now = std::chrono::system_clock::now(); // get current time
log(now, "logAndAdd"); // make log entry
names.emplace(std::forward<T>(name)); // add name to global data structure
}
// Calls in different ways
std::string petName("Darla"); // as before
logAndAdd(petName); // (1) as before, copy lvalue into multiset
logAndAdd(std::string("Persephone")); // (2) move rvalue instead of copying it
logAndAdd("Patty Dog"); // (3) create std::string in multiset instead
// of copying a temporary std::string
重载了万能引用函数去解决面临的另一个问题
但实际上中,也许使用者可能只能通过一个index来调用logAndAdd,而没有直接访问一个名字的可能。
为了支持这种用法,重载了之前的函数logAndAdd如下(后面会说明这不是一个好主意)
// A function declarition returning name corresponding to idx
std::string nameFromIdx(int idx);
void logAndAdd(int idx) { // new overload
auto now = std::chrono::system_clock::now();
log(now, "logAndAdd");
names.emplace(nameFromIdx(idx));
}
// Usages
std::string petName("Darla"); // as before
logAndAdd(petName); // as before, these
logAndAdd(std::string("Persephone")); // calls all invoke
logAndAdd("Patty Dog"); // the T&& overload
logAndAdd(22); // calls int overload
这里需要注意的是,在调用logAndAdd(22);的时候,为什么最终调用的是logAndAdd(int idx)的重载函数,而不是logAndAdd(T&& name),似乎看起来logAndAdd(T&& name)经过实例化之后,也可以得到logAndAdd(int &&),好像也可以调用?
原因就是,C++标准指出,当一个模板函数经过实例化之后得到的函数,和一个非模板的函数,对于同一个函数调用是同样好的匹配的时候,这个普通的非模板的函数胜出。
In situations where a template instantiation and a non-template function (i.e., a “normal” function) are equally good matches for a function call, the normal function is preferred.
重载了万能引用函数引起的问题
但重载了上面的万能引用函数之后,如果有下面的使用,就可能产生问题。
short nameIdx;
/* ... */ // give nameIdx a value
logAndAdd(nameIdx); // error!
产生问题的原因是,带有万能引用参数的重载函数经过类型推导之后,会得到logAndAdd(short&),而如果要调用带有int参数的重载函数,需要进行一次类型提升转换(promotion),即从short转换到int。
显然带有万能引用参数的重载函数是最佳匹配,从而导致编译器最终会使用它。
那么当函数执行到names.emplace(std::forward<T>(name));的时候,显然错误就发生了,因为std::string没有从一个short进行构造的构造函数!
由此可以看出,带有万能引用参数的重载函数是非常“贪婪”的,它经过实例化可以生成匹配几乎任何类型参数的实例。(只有少数例外)
Functions taking universal references are the greediest functions in C++. They instantiate to create exact matches for almost any type of argument.
所以结论是,不要重载带有万能引用的函数。
另一个类似的陷阱
Scott Meyers还举了另外一个例子,perfect forwarding constructor,说明这个类似的陷阱。
class Person {
public:
// Perfect forwarding ctor; initializes data member by initialization list int ctor
template<typename T>
explicit Person(T&& n) : name(std::forward<T>(n)) {}
// A normal ctor
explicit Person(int idx) : name(nameFromIdx(idx)) {}
/* ... */
private:
std::string name;
};
这里可能发生的错误,和前面提到的一样,如果传入的是integral type(e.g., std::size_t, short, long, etc.),就会发生错误。
而这里更严重的问题是,尽管这里的带有模板的构造函数在经过实例化之后可能产生对应的拷贝构造函数和移动构造函数,但这不会影响编译器在满足条件的时候,依然会帮着生成拷贝构造函数和移动构造函数。这时候Person这个class看起来就像是下面这样。
class Person {
public:
// Perfect forwarding ctor; initializes data member by initialization list int ctor
template<typename T>
explicit Person(T&& n) : name(std::forward<T>(n)) {}
// A normal ctor
explicit Person(int idx) : name(nameFromIdx(idx)) {}
Person(const Person& rhs); // copy ctor (compiler-generated)
Person(Person&& rhs); // move ctor (compiler-generated)
/* ... */
private:
std::string name;
};
如果此时有如下的代码,问题就产生了。
Person p("Nancy");
auto cloneOfP(p); // create new Person from p; this won't compile!!!
这里实际上编译器会最终决定调用经过实例化之后的带有万能引用的构造函数,而不是编译器帮忙生成的拷贝构造或移动构造。
不调用移动构造函数( Person(Person&& rhs))的原因是显然的,因为p是左值。
而不调用拷贝构造(Person(const Person& rhs))的原因是,带有万能引用的构造函数经过实例化之后,会得到Person(Person& rhs),(没有const),那么根据C++标准,这就是比const Person &rhs更好的匹配,所以就调用了它。那么最后得到的结果就是,在初始化列表中,用一个Person &去初始化std::string,这显然是错误的。
如果我们的调用代码变成了如下的形式,结果就正常了。
const Person p("Nancy"); // object is now const
auto cloneOfP(p); // calls copy constructor!
为什么?和前面分析的一样,这时候编译器(在满足条件的情况下)同样帮助生成拷贝构造(Person(const Person& rhs))和移动构造( Person(Person&& rhs))。而此时如果带有万能引用的构造函数经过实例化,同样可以得到构造函数Person(const Person& rhs),这也同样是拷贝构造,但根据C++标准,如果一个模板函数和非模板重载函数是同样好的匹配,非模板函数胜出,所以最终调用了编译器帮助生成的拷贝构造,所以编译通过了。
同样的问题,在有类继承的情况下同样会发生。
class SpecialPerson: public Person {
public:
// copy ctor; calls base class forwarding ctor!
SpecialPerson(const SpecialPerson& rhs) : Person(rhs) { /* ... */ }
// move ctor; calls base class forwarding ctor!
SpecialPerson(SpecialPerson&& rhs) : Person(std::move(rhs)) { /* ... */ }
};
这里,子类SpecialPerson的拷贝构造和移动构造的初始化列表中,使用rhs来初始化父类,仍然会导致调用经过实例化之后的带有万能引用的构造函数(而不是Person中由编译器帮助生成的拷贝和移动构造函数),显然std::string也没有通过SpecialPerson来初始化的构造函数,因此编译失败了。
Things to Remember
Overloading on universal references almost always leads to the universal reference overload being called more frequently than expected.
Perfect-forwarding constructors are especially problematic, because they’re typically better matches than copy constructors for non-
constlvalues, and they can hijack derived class calls to base class copy and move constructors.
Item 27: Familiarize yourself with alternatives to overloading on universal references.
前面一本节讲述了重载带有万能引用参数的函数可能造成的一些问题,不管是独立函数还是成员函数(尤其是构造函数)。但同样地,从侧面说明只要按照我们所预期的方式,重载这样的函数可能是有用的。
本节讲述了,如何通过设计来避免重载带有万能引用参数的函数,或者通过限制参数类型的方式,达到这样的目的。
本节用到的标准库的编译期函数
std::enable_if
std::is_same
std::decay
std::remove_reference
std::is_base_of
static_assert
5种办法
本节总共提到了5种方式来避免重载带有万能引用参数的函数
Abandon overloading
Pass by
const T&Pass by value
Use Tag dispatch
constraining template eligibility
例子仍然是上一节(item 26)中所提到的例子:有一个logAndAdd的函数,接受一个std::string的参数,但有时候又想通过一个integral的index(通过一个函数获得std::string)来调用这个函数
std::multiset<std::string> names; // global data structure
// A function declarition returning name corresponding to idx
std::string nameFromIdx(int idx);
void logAndAdd(const std::string& name) {
auto now = std::chrono::system_clock::now(); // get current time
log(now, "logAndAdd"); // make log entry
names.emplace(name); // add name to global data structure
}
Abandon overloading
不做重载函数,而使用两个不同名字的函数,显然是最直接的办法之一。比如单独写两个函数logAndAddName给std::string参数,而logAndAddNameIdx给int使用。
但这个不能解决构造函数带有万能引用参数的问题。
Pass by const T&
可以使用const T&来代替万能引用T&&,这是C++98的方式,但这就会导致总是发生拷贝,从而不能达到我们提高性能的目的(避免不必要的拷贝)
Pass by value
不再使用万能引用,而直接使用值传递代替,这是另一种看起来反直觉的办法。Scott Meyers在item 41中会再讨论它。
显然,没有了万能引用,自然不存在万能引用会生成最佳匹配但不是正确匹配重载函数的问题了。
class Person {
public:
// replaces T&& ctor; see Item 41 for use of std::move
explicit Person(std::string n) : name(std::move(n)) {}
explicit Person(int idx) : name(nameFromIdx(idx)) {} // as before
private:
std::string name;
};
Use Tag dispatch
因为pass by lvalue-reference-to-const 和 pass by value都不支持万能引用,但我们使用万能引用的目的就是为了完美转发,所以如果我们不得不使用万能引用来实现完美转发时,tag dispatch 是一种既能实现万能引用,又能实现重载的办法。
这种办法的核心是,使用了两个函数(实际上是一个入口函数和两个具体实现的重载函数)
第一个函数带有一个万能引用参数,但只是一个入口函数,它不实现具体的功能,它只根据万能引用的类型得出需要传递给第二个函数的参数
第二个函数实际上是两个重载函数,带有一个万能引用参数和一个tag参数,它根据tag参数的不同,调用不同的逻辑实现
template<typename T>
void logAndAdd(T&& name) {
logAndAddImpl(std::forward<T>(name),
std::is_integral<typename std::remove_reference<T>::type>());
}
template<typename T> // non-integral argument: add
void logAndAddImpl(T&& name, std::false_type) { // it to global data
auto now = std::chrono::system_clock::now();
log(now, "logAndAdd");
names.emplace(std::forward<T>(name));
}
std::string nameFromIdx(int idx); // returning name corresponding to idx
void logAndAddImpl(int idx, std::true_type) { // integral argument: look up name
logAndAdd(nameFromIdx(idx)); // and call logAndAdd with it
}
由上面的代码可以看到,第一个函数logAndAdd只是一个入口函数,它的万能引用参数接受任何类型的参数。此外它还根据万能引用参数的类型,在编译期间其他计算得到T是否为integral类型(std::size_t,int,short等),并把它当做一个tag,从而调用真正实现了逻辑的重载函数logAndAddImpl。
logAndAddImpl是两个重载函数,一个给non-integral使用,另一个给integral使用。它们是通过std::false_type和std::true_type这两个tag来区分并调用不同的重载函数。
std::false_type和std::true_type实际上是用来表示bool的true和false的std::integral_constant的实例(instantiation)。
之所以使用std::false_type和std::true_type,而不是使用true和false,这是因为true和false它们是runtime的变量,我们想要的是在编译期间(compile-time)就能由编译器决定使用哪个重载函数的编译器变量。
这两个参数的在编译期间,可以由std::is_integral得出,正如代码中所述。
而加上std::remvoe_reference的原因是,int和int&是不同的类型,int是整型,而int&是引用,但如果传递给万能引用参数的是int,那么得到的显然会是int&而不是int,而我们依然希望把这个int&传递给函数nameFromIdx,所以需要把它等价于int,那么就需要函数std::remvoe_reference除去它的引用属性。
给non-integral使用的重载函数就是之前的逻辑,记录时间,并把name这个std::string加入到names中。
而给integral使用的重载函数,需要把传入的idx通过函数nameFromIdx转换为std::string,从而再次调用入口函数logAndAdd(T&& name),然后再回到调用non-integral的函数,从而完成真正的添加功能。
需要注意的是,两个带有tag参数的重载函数的第二个参数,甚至都没有给它们命名,这是因为我们想让编译器在编译期间就识别它们没有用而把它们优化掉(因为它们在runtime时没有任何作用),所以这第二个参数的目的仅仅是在编译期间使得编译器能够正确识别并调用对应的重载函数。
通过创建正确的tag来把真正的工作分配给正确的重载函数,这就是所谓的 tag dispatch 技术。C++的模板元编程(template metaprogramming)中经常用到这种技术。
Constraining templates that take universal references
关键字(用到的标准库的编译期函数)
std::enable_if
std::is_same
std::decay
std::remove_reference
std::is_base_of
static_assert
最后一种,也是比较复杂的一种技术,就是通过限制模板参数的类型来使用万能引用。
在item 26中提到过,就算是有使用万能引用的构造函数,在满足条件的情况下,编译器依然会忠实地生成对应的拷贝(或移动)构造函数,哪怕那个带有万能引用参数的构造函数经过实例化之后,得到的就是拷贝(或移动)构造函数。
在这种情况下,通过tag dispatch是没有办法做到的,因为我们没有办法限制编译器来生成这些重载函数(构造函数)。
或者说,发生问题的根源并不是因为有这些重载函数,而是因为带有万能引用参数的函数太“贪婪“了,它匹配了太多我们不希望它进行匹配的函数重载,从而导致预期之外的问题。
那么关键就是,我们如何限制带有万能引用参数的函数,使得它只在某些条件下去匹配到我们希望它匹配的类型,而不要那么地“贪婪”?
这就要用到std::enable_if,它强迫编译器装作对某些类型的模板不存在(disabled),而std::enable_if就告诉编译器满足了哪些指定条件的类型的模板,才可以当做可用的。
std::enable_ifgives you a way to force compilers to behave as if a particular template didn’t exist.Such templates are said to be disabled. By default, all templates are enabled, but a template using
std::enable_ifis enabled only if the condition specified bystd::enable_ifis satisfied.
std::enable_if在这里的使用的样板如下
class Person {
public:
template<typename T, typename = typename std::enable_if<CONDITION>::type>
explicit Person(T&& n);
private:
std::string name;
};
这里的CONDITION是指某个条件(编译期间)。
根据item 26的例子,我们是希望用不是Person类型的变量传入万能引用的构造函数,而是Person类型的变量传入编译器生成的拷贝(或移动)构造函数。所以就有以下的代码
class Person {
public:
template<typename T,
typename = typename std::enable_if<
!std::is_same<Person, typename std::decay<T>::type>::value
>::type
>
explicit Person(T&& n);
Person(const Person&); // compiler might generate
Person(const Person&&); // compiler might generate
private:
std::string name;
};
这里的CONDITION实际上就是!std::is_same<Person, typename std::decay<T>::type>::value。
std::is_same<T1, T2>::value表示T2是不是T1的类型(是为true,不是为false)。
std::decay表示要去掉T的引用属性(reference)和常量或易变属性(cv-qualifier)。
使用!std::is_same<T1, T2>::value是我们想要的,因为我们想要限制不是Person类的才使用有万能引用的构造函数。
而使用std::decay<T>::type的原因是,Person和Person&(或const Person、const Person&等)是不同的类型,这就可能导致比如!std::is_same<Person, Person&>::value为true,从而把Person&传入到了万能引用的构造函数,而这恰恰是我们要避免的。所以就需要把其上的引用属性(reference)和常量或易变属性(cv-qualifier)都去除掉之后在进行比较类型本身才行。
这样,我们限制了在编译期间传入带有万能引用参数的构造函数的类型,从而实现了限制非预期的参数调用它的目的。
可是,这样的情况遇到继承关系的时候,还是会出问题。正如item 26所述,如果SpecialPerson继承自Person,那么如果把一个SpecialPerson的object传入上面Person的构造函数,最后依然造成了我们本想避免的问题(因为最后会拿一个SpecialPerson的对象去初始化std::string)。
这时候就要用到std::is_base_of来代替std::is_same。
这是由于对于任何一个类型T,std::is_same<T, T>::value显然是true,但实际上std::is_base_of<T, T>::value也是true,因为我们认为T就是继承自它自己本身(嗯…),而使用std::is_base_of又可以用来判断是否是继承的关系,所以使用std::is_base_of来代替std::is_same,得到下面的代码。
class Person {
public:
template<typename T,
typename = typename std::enable_if<
!std::is_base_of<Person, typename std::decay<T>::type>::value
>::type
>
explicit Person(T&& n);
Person(const Person&); // compiler might generate
Person(const Person&&); // compiler might generate
private:
std::string name;
};
最后Scott Meyers提到,这个构造函数引起的函数重载问题,实际上是我们为了区分使用int还是std::string来调用logAndAdd函数时带来的问题,而在这个例子中,我们实际上还要区分是否是int,那么就需要再加入对integral type的编译期判断,如下(C++11和C++14不同的写法)。
// In C++11 style
class Person {
public:
template<typename T,
typename = typename std::enable_if<
!std::is_base_of<Person, typename std::decay<T>::type>::value
&&
!std::is_integral<typename std::remove_reference<T>>::value
>::type
>
explicit Person(T&& n);
Person(const Person&); // compiler might generate
Person(const Person&&); // compiler might generate
private:
std::string name;
};
// In C++14 style
class Person {
public:
template<typename T,
typename = std::enable_if_t<
!std::is_base_of<Person, std::decay<T>::type>::value
&&
!std::is_integral<std::remove_reference_t<T>>::value
>::type
>
explicit Person(T&& n);
Person(const Person&); // compiler might generate
Person(const Person&&); // compiler might generate
private:
std::string name;
};
代价
使用perfect forwarding的好处是,可以在合适情况下避免不必要的拷贝。
但使用perfect forwarding也有两个可能的影响
第一个是,有时候的确不能使用perfect forwarding
第二个是,因为完美转发的层层传递的原因,也许只有传递到最后一层的时候,编译器才发现问题,然后报错,但这时候报告的错误信息十分冗长而且难懂,从而很难定位问题。
Scott Meyers举例说明了第二个影响。
Person p(u"Konrad Zuse"); // "Konrad Zuse" consists of characters of type const char16_t
上面的代码是试图使用const char16_t[12]来初始化std::string,按照前面的代码实现,它的确会进入到带有万能引用参数的构造函数,然后被层层传递,直到最后初始化std::string name的时候才出错。
因为std::string是用char实现的,不是char16_t,所以报错是正常的,但这时候根据Scott的说法,编译器报告了一个长达160行的错误信息,这就十分难懂且令人困惑了。
所以,Scott提到的一个用来缓解第二个影响的办法是,加入static_assert并写明信息,从而使得我们能够看懂问题出现在什么地方。
// In C++11 style
class Person {
public:
template<typename T,
typename = typename std::enable_if<
!std::is_base_of<Person, typename std::decay<T>::type>::value
&&
!std::is_integral<typename std::remove_reference<T>>::value
>::type
>
explicit Person(T&& n) {
// assert that a std::string can be created from a T object
static_assert(std::is_constructible<std::string, T>::value,
"Parameter n can't be used to construct a std::string");
}
Person(const Person&); // compiler might generate
Person(const Person&&); // compiler might generate
private:
std::string name;
};
Things to Remember
Alternatives to the combination of universal references and overloading include the use of distinct function names, passing parameters by lvalue-reference-to-const, passing parameters by value, and using tag dispatch.
Constraining templates via
std::enable_ifpermits the use of universal references and overloading together, but it controls the conditions under which compilers may use the universal reference overloads.Universal reference parameters often have efficiency advantages, but they typically have usability disadvantages.
Item 28: Understand reference collapsing.
本节主要讲述了发生了引用折叠(reference collapsing)的四种情况,以及万能引用中的类型T到底被推导成了什么类型。
万能引用被推导成了什么类型?
template<typename T>
void func(T&& param);
上面的函数模板是典型的万能引用的使用场景,而模板参数T被推导出来的类型关系到函数参数param的左值还是右值类型。
The deduced template parameter
Twill encode whether the argument passed toparamwas an lvalue or an rvalue.
encode mechanism(编码规则,即T被推导称为的类型的规则)
如果传入的是 lvalue(左值),那么
T被推导成 lvalue reference(左值引用)如果传入的是 rvalue(右值),那么
T被推导成 non-reference(非引用)
注意这里的规则是不对称的。
The encoding mechanism is simple.
When an lvalue is passed as an argument,
Tis deduced to be an lvalue reference. When an rvalue is passed,Tis deduced to be a non-reference.Note the asymmetry: lvalues are encoded as lvalue references, but rvalues are encoded as non-references.
下面是几个例子
Widget widgetFactory(); // function returning rvalue
Widget w; // a variable (an lvalue)
func(w); // call func with lvalue; T deduced to be Widget&
func(widgetFactory()); // call func with rvalue; T deduced to be Widget
引用折叠(reference collapsing)
发生引用折叠的情况有四种
实例化模板的时候
auto变量类型推导的时候typedef的时候decltype的时候
C++编译器禁止我们写引用的引用,但是编译器却可以产生引用的引用。而引用折叠产生的原因是需要进行类型推导。
比如前面的例子,根据万能引用推导的类型,会导致编译器产生引用的引用。
template<typename T>
void func(T&& param);
func(w); // invoke func with lvalue; T deduced as Widget&
上面经过类型推导之后的等效的代码如下,这里编译器就产生了引用的引用。
void func(Widget& && param);
为了解决这种问题,编译器采用了引用折叠办法。因为有两种引用(lvalue reference和rvalue reference),所以引用的引用就有四种组合。
引用折叠的规则是:只要有一个是左值引用(lvalue reference),最后的结果就是左值引用;否则就是右值引用。
If either reference is an lvalue reference, the result is an lvalue reference. Otherwise (i.e., if both are rvalue references) the result is an rvalue reference.
std::forward的原理
完美转发,std::forward,就是只有在参数是右值的时候,才将参数本身转换为右值。
std::forward概念上的实现如下
template<typename T> // in namespace std
T&& forward(typename remove_reference<T>::type& param) {
return static_cast<T&&>(param);
}
假如有个函数带有万能引用参数,使用了完美转发
template<typename T>
void f(T&& fParam) {
/* ... */ // do some work
someFunc(std::forward<T>(fParam)); // forward fParam to someFunc
}
当绑定到左值的时候
当传入f的参数是左值(Widget)的时候,根据万能引用的类型推导规则,T被推导为Widget&,就会有如下(逻辑上的)代码
Widget& && forward(typename remove_reference<Widget&>::type& param) {
return static_cast<Widget& &&>(param);
}
进一步根据std::remove_reference的结果有
Widget& && forward(Widget& param) {
return static_cast<Widget& &&>(param);
}
再根据引用折叠个规则,有
Widget& forward(Widget& param) {
return static_cast<Widget&>(param);
}
所以,最后返回的就是一个左值引用。
当绑定到右值的时候
当传入f的参数是右值(Widget)的时候,根据万能引用的类型推导规则,T被推导为Widget(非引用),就会有如下(逻辑上的)代码
Widget&& forward(typename remove_reference<Widget>::type& param) {
return static_cast<Widget&&>(param);
}
进一步根据std::remove_reference的结果有
Widget&& forward(Widget& param) {
return static_cast<Widget&&>(param);
}
此时已经没有引用的引用了,就是最终结果。
所以,最终返回了传入参数的右值引用。
这里因为std::forward函数返回右值引用是右值,所以std::forward把传入的参数fParam(本身是左值)转换成了右值,并传入了sameFunc。再联系到传入f函数的也右值,所以最终实现了完美转发。
Rvalue references returned from functions are defined to be rvalues, so in this case,
std::forwardwill turnf’s parameterfParam(an lvalue) into an rvalue. The end result is that an rvalue argument passed tofwill be forwarded to someFunc as an rvalue, which is precisely what is supposed to happen.
auto类型推导
和万能引用的类型推导类似,如果是auto&&,那么规则是
如果是绑定到了左值(lvalue),那么
auto被推导为左值引用T&如果是绑定到了右值(rvalue),那么
auto被推导为非引用类型
例子如下
Widget widgetFactory(); // function returning rvalue
Widget w; // a variable (an lvalue)
auto &&w1 = w; // (1)
auto &&w1 = widgetFactory(); // (2)
中第(1)个,因为w是左值,所以auto被推导为Widget&,那么就有
Widget& &&w1 = w;
根据引用折叠规则,w1最终就是左值引用。
第(2)个,,因为widgetFactory返回的是右值,所以auto被推导为Widget(非引用类型),那么就有
Widget &&w2 = w;
这里已经没有引用折叠了,所以w2最终就是右值引用。
万能引用的本质
万能引用不是新的引用,而是在满足了两个条件的上下文环境中的一个右值引用
类型推导把左值和右值做了区分
当引用折叠发生的时候
A universal reference isn’t a new kind of reference, it’s actually an rvalue reference in a context where two conditions are satisfied:
Type deduction distinguishes lvalues from rvalues. Lvalues of type
Tare deduced to have typeT&, while rvalues of typeTyieldTas their deduced type.Reference collapsing occurs.
引用折叠发生在typedef时
template<typename T>
class Widget {
public:
typedef T&& RvalueRefToT;
/* ... */
};
当我们使用Widget&来实例化这个类模板的时候,就会得到
typedef Widget& && RvalueRefToT;
根据引用折叠的规则,它就是
typedef Widget& RvalueRefToT;
所以,最终RvalueRefToT实际上是个左值引用,而不是它表面上看起来(或者是像它的名字一样)的好像是个右值引用。
Things to Remember
Reference collapsing occurs in four contexts: template instantiation,
autotype generation, creation and use oftypedefs and alias declarations, anddecltype.When compilers generate a reference to a reference in a reference collapsing context, the result becomes a single reference. If either of the original references is an lvalue reference, the result is an lvalue reference. Otherwise it’s an rvalue reference.
Universal references are rvalue references in contexts where type deduction distinguishes lvalues from rvalues and where reference collapsing occurs.
Item 29: Assume that move operations are not present, not cheap, and not used.
本节的主要目的是,强调移动操作并不是总是可以使用的,或者并不是总比拷贝快。
使用移动操作其实有条件的,而且有时候因为条件限制,不一定比拷贝更快。
C++11确实对C++98的STL做了彻底的改进,以便支持移动语义(操作),但确实有的地方是不适合或者没有办法使用移动语义(操作),所以并不是所有地方都支持了移动语义(操作)。
Scott Meyers举例说明了这几点。
std::array的移动操作
像std::vector这样的容器,可以简单地认为它有一个指向堆上内存的指针,所以当需要移动操作的时候,就能直接把指针所指向的地址赋值给target std::vector,并把source的指针置空。
std::vector<Widget> vw1;
/* ... */ // put data into vw1
// move vw1 into vw2. Runs in constant time. Only ptrs in vw1 and vw2 are modified
auto vw2 = std::move(vw1);
但std::array没有这样的指针,因为它把数据存储在了对象本身里(即栈上),所以,std::array的移动操作本质上是拷贝操作。但有一点区别是,如果它里面的元素支持移动操作,那么std::array的移动操作就还是要比它的拷贝操作快一些,但这比我们预期的像std::vector那样的快是差一些的。
std::array<Widget, 10000> aw1;
/* ... */ // put data into vw1
// move aw1 into aw2. Runs in linear time. All elements in aw1 are moved into aw2
auto aw2 = std::move(aw1);
std::string的移动操作
很多字符串的实现采用了所谓的SSO(small string optimization ),它的目的就是为了提高性能,这样可以在操作比较操作短字符串时,就直接使用其对象本身带有的栈上的一个buffer存储,而避免去堆上分配内存。
很显然,对于这样的std::string,移动本质上就是拷贝,所以移动并不比拷贝更快。
有异常的move操作
STL中为了保证C++98的代码中依赖不抛异常的拷贝操作的特性不被破坏,即使有对应的移动操作比拷贝操作更快(而且实现同样功能),编译器也会被迫使用拷贝操作而不是移动操作,这是因为移动操作没有被声明为noexcept。
总结
总的来说,有以下几个原因导致移动操作不可用或没有更快
No move operations
Move not faster
Move not usable
Source object is lvalue
Item 30: Familiarize yourself with perfect forwarding failure cases.
本节主要讨论几种完美转发失败的情况
Braced initializers
什么是 perfect forwarding?
完美转发,顾名思义,就是一个函数把它的参数转发给另外一个函数。
目的是,使得第二个函数接收到的参数,和第一个函数接收到的参数,是相同的。
完美转发不包括值传递,原因是值传递是拷贝了原先传给第一个函数的参数,而我们想要的是,第二个函数操作的是传入第一个函数的原始参数。
完美转发也不包括指针传递。
所以,完美转发只是引用传递。
而且完美转发只能是万能引用,原因是,我们要转发参数的类型、左右值属性以及它们是否是const或volatile,而只有万能引用才能满足这个条件。
基本的转发样板
本文所讨论的转发样板如下
template<typename T>
void fwd(T&& param) { // accept any argument
f(std::forward<T>(param)); // forward it to f
}
如果是基于可变参数的转发,样板如下
template<typename... Ts>
void fwd(Ts&&... params) { // accept any arguments
f(std::forward<Ts>(params)...); // forward them to f
}
完美转发失败的两个原因
后面讨论的完美转发失败的两个原因,从概念上来讲分别是
Compilers are unable to deduce a type
Compilers deduce the “wrong” type
Braced initializersr
如果f的声明是
void f(const std::vector<int>& v);
那么给f传入使用花括号列表的参数,f是可以正常调用的(隐式转换为std::vector)
f({ 1, 2, 3 }); // fine, "{1, 2, 3}" implicitly converted to std::vector<int>
但如果给fwd传入使用花括号列表的参数,编译就失败
fwd({ 1, 2, 3 }); // error! doesn't compile
这是完美转发失败的一个例子。
前面f({1,2,3})编译成功的原因是,编译器看到了在调用处的实参,并且也知道函数f声明的形参,然后把形参和实参做了比较,并查看是否兼容,而且,如果需要的话,会做隐式的转换。
而fwd({1,2,3})编译失败的原因是,编译器中编译f(std::forward<T>(param))这句调用的时候,它查看的并不是传给fwd的(实际)参数,而是经过类型推导的参数,然后才和函数f声明的形参进行比较。
根据C++标准指出,把一个braced initializer传给一个形参声明不是std::initializer_list的函数模板,会得到一个”non-deduced context”(不可推导的内容)。这里fwd的形参声明不是std::initializer_list,所以把一个braced initializer({1, 2, 3})传递给它,导致编译器被禁止推导类型,从而导致编译失败。
解决的办法是,使用auto。原因是使用braced initializer初始化一个auto声明的变量时,编译器被允许将其推导为一个std::initializer_list,然后再将这个变量传入fwd即可。
auto il = { 1, 2, 3 }; // il's type deduced to be std::initializer_list<int>
fwd(il); // fine, perfect-forwards il to f
0 or NULL as null pointers
Item 8中曾经提到,编译器实际上是把0和NULL当做int(或int-like)类型的,只有当不得已的时候才被迫转换成指针。
而当把0和NULL当做参数传递时,前面的类型推导就会把它们推导成int(或int-like)类型,而不是我们想要的指针类型。
解决的办法也很简单,就是使用nullptr。
Declaration-only integral static const data members
对于static const的integral类型的类的静态成员变量,可以只声明不定义,编译器会帮忙处理(是把所有用到的地方做替换,而不是帮忙补上定义)。
但如果要使用到指向它的指针的时候(需要取得存储地址),那么就会在链接的阶段失败,因为没有定义!
当然有些编译器对这种情况做了支持,即在没有定义的情况下也可以取得其地址(编译器帮了忙)
As a general rule, there’s no need to define integral
staticconstdata members in classes; declarations alone suffice. That’s because compilers performconstpropagation on such members’ values, thus eliminating the need to set aside memory for them.If that value’s address were to be taken (e.g., if somebody created a pointer to it), then that variable would require storage (so that the pointer had something to point to), and the code above, though it would compile, would fail at link-time until a definition for that variable was provided.
如果有一个static const静态成员变量(只声明未定义),以及函数f的声明如下
class Widget {
public:
static const std::size_t MinVals = 28; // MinVals' declaration
};
void f(std::size_t val);
那么直接使用Widget::MinVals来调用f是可以的(因为编译器做了替换)
f(Widget::MinVals); // fine, treated as "f(28)"
但如果把它传入fwd,在链接的时候就会失败
fwd(Widget::MinVals); // error! shouldn't link
原因是,fwd的形参是万能引用,它是引用,所以它本质上和指针是同一回事,那么指针所指向的内容就得有内存的地址,否则就链接失败了。
但因为有的编译器对这种情况做了特殊处理,所以可能链接也会成功。如果编译器没有处理,就简单地给这个成员变量加上定义即可。
const std::size_t Widget::MinVals; // in Widget's .cpp file
Overloaded function names and template names
如果一个函数f的参数是一个函数指针,那么其实可以将合适的函数的名字传入函数f,由编译器来帮助处理。
因为编译器可以根据函数的名字找到对应的函数的地址,从而得到对应的函数指针,哪怕是重载函数也可以。
假如前面提到的函数f接收一个函数指针作为参数,那么函数f的声明可以如下
void f(int (*pf)(int)); // pf = "processing function"
而且更简单地,可以写成没有指针的语法形式如下
void f(int pf(int)); // declares same f as above
现在,假如有两个重载函数,其中第一个接收一个int参数,并返回一个int;第二个有两个int参数,并且返回一个int。
int processVal(int value);
int processVal(int value, int priority);
那么实际上,我们可以直接把函数名称processVal当做参数传递给函数f实现函数调用。
尽管函数f的参数是一个函数指针,但编译器知道f的参数类型是什么,因此可以通过函数名字得出对应的函数地址并得到函数指针,哪怕是多个重载函数,编译器也可以找到。
但如果我们把这个processVal函数名字传递给前面的fwd函数,并期望能够实现完美转发,就发现会失败了。
fwd(processVal); // error! which processVal?
原因是,fw是一个函数模板,它本身没有关于参数类型的任何信息,它得需要从一个具体的传入它的参数身上进行类型推导,而恰恰processVal这个函数名字没有关于类型的任何信息(因为有多个重载),所以编译器没有知道应该选择哪一个。
类似的,如果我们要给fwd函数传入一个函数模板,这正如前面所述,是不正确的。因为传入的函数模板不代表某一个单独的具体的函数,而是好多不同(参数类型/返回类型)的函数。
template<typename T>
T workOnVal(T param) { /* ... */ } // template for processing values
fwd(workOnVal); // error!!! which workOnVal instantiation?
所以,如果要把一个重载函数或是函数模板当做参数传递给完美转发的函数,需要手动的具体指明是哪一个重载函数,或是哪一个函数模板的实例化。
下面分别是指明了一个具体的重载函数,以及一个具体的实例化了的函数模板,把它们当做参数传入再完美转发。
// make typedef; see Item 9
using ProcessFuncType = int (*)(int);
ProcessFuncType processValPtr = processVal; // specify needed signature for processVal
fwd(processValPtr); // fine
fwd(static_cast<ProcessFuncType>(workOnVal)); // also fine, see above for workOnVal
对应第一个重载函数,首先使用了alias的using语法,得到了一个对应的具体的重载函数signature,然后就可以传入带有万能引用的函数fwd进行转发了。
第二个传入的是一个实例化了的模板函数workOnVal,它是使用了static_cast<int(*)(int)>对其进行了实例化。
Bitfields
一个bitfield的例子如下,它把一个uint32_t的不同部分做了区分。
struct IPv4Header {
std::uint32_t version:4,
IHL:4,
DSCP:6,
ECN:2,
totalLength:16;
/* ... */
};
而C++标准明确指出:非const引用不能绑定到bit field上。
A non-
constreference shall not be bound to a bit-field.
原因是因为bitfield可以是机器字的任意部分(比如,bits 3-5 of a 32-bit int),所以没有办法直接取得它们对应的地址。
而且C++指出最短的可以使用指针指向的是char类型。
C++ dictates that the smallest thing you can point to is a
char
而由于引用和指针的底层实现是一回事,所以指针没有办法指向一个bit field,同样地,一个引用也没有办法绑定到一个bit field。
因此,如果前面的函数f的声明如下
void f(std::size_t sz); // function to call
那它实际上可以使用如下字段调用函数f
IPv4Header h;
f(h.totalLength); // fine
但是,却不能使用这样的字段调用函数fwd(因为它带有万能引用),因为引用的底层实现和指针是一回事,而指针不可能指向某一个bit field(就如前面所述)
fwd(h.totalLength); // error!!!
解决的办法也很简单,可以接收bit field的参数的有两种,一种是通过值传递(pass-by-value)的参数,另一种是const引用。
所以,要么是通过值传递的办法,使得参数拷贝传入的bit field;要么是通过const引用的办法,把这个const引用绑定到一个标准的integral type(比如int)对象上,并且保证传入bit field和那个被绑定的integral type对象的bit field相同。
这里使用了第一种办法,如下。
// copy bitfield value; see Item 6 for info on init. form
auto length = static_cast<std::uint16_t>(h.totalLength);
fwd(length); // forward the copy
Things to Remember
Perfect forwarding fails when template type deduction fails or when it deduces the wrong type.
The kinds of arguments that lead to perfect forwarding failure are braced initializers, null pointers expressed as
0orNULL, declaration-only integralconststatic data members, template and overloaded function names, and bitfields.
Chapter 6 Lambda Expressions
什么是 lambda?
lambda 是一个表达式,是源代码的一部分。
闭包(closure) 是lambda创建的一个运行时的对象,根据不同的模式,它赋值或者引用了捕获的数据
闭包类(closure class或closure type) 是一个类(class),**闭包(closure)是这个类的一个实例化。编译器会给每个lambda表达式生成唯一的闭包类。Lambda内部的语句就变成了这个类的成员函数的可执行指令。
A lambda expression is just that: an expression. It’s part of the source code.
A closure is the runtime object created by a lambda. Depending on the capture mode, closures hold copies of or references to the captured data.
A closure class is a class from which a closure is instantiated. Each lambda causes compilers to generate a unique closure class. The statements inside a lambda become executable instructions in the member functions of its closure class.
lambda生成的的闭包,除了可以当做诸如std::find_if等函数的参数外,还可以被复制,所以可以有多个闭包是同一个lambda生成的同一个闭包类型。
However, closures may generally be copied, so it’s usually possible to have multiple closures of a closure type corresponding to a single lambda.
{
int x; // x is local variable
// c1 is copy of the closure produced by the lambda
auto c1 = [x](int y) { return x * y > 55; };
auto c2 = c1; // c2 is copy of c1
auto c3 = c2; // c3 is copy of c2
}
Item 31: Avoid default capture modes.
C++11的lambda有两种默认的捕获模式
引用捕获(default by-reference)
值捕获(default by-value)
默认引用捕获可能造成悬空的引用,默认的值捕获实际上也会导致悬空的引用(而且也不像它看上去那样是自洽的。)
C++11中lambda捕获的引用或者变量,**都是在lambda被定义处范围(scope)的局部变量或者参数。**也就是说,lambda生成的closure中会包含这些局部变量或参数的引用或变量拷贝。
这也同时说明,lambda是不会捕获static变量的(无论是class的还是全局的)
Captures apply only to non-
staticlocal variables (including parameters) visible in the scope where the lambda is created.
捕获引用可能造成引用“悬空”
C++11中lambda捕获的引用或者变量,**都是在lambda被定义处范围(scope)的局部变量或者参数。**也就是说,lambda生成的closure中会包含这些局部变量或参数的引用或变量拷贝。
这意味着,如果一个lambda生成的closure的生命周期,如果比捕获的引用(或变量)生命周期更长,或者超出了它们的定义范围,那么这个引用就可能“悬空”。(后面会看到,如果是值捕获,且是指针的话,同样可能悬空)
Scott Meyers举了个例子,定义了一个全局的存储std::function的std::vector,它用来存储lambda生成的那些closure。
using FilterContainer = std::vector<std::function<bool(int)>>;
FilterContainer filters; // filtering funcs
如果按照下面的方式,使用默认捕获引用,就会导致,离开这个函数之后,所引用的divisor就不存在了(因为引用了一个局部变量,而离开这个函数之后那个局部变量就不存在了),这时候再使用所存储的closure,就会发生未定义的行为(undefined behavior)
void addDivisorFilter() {
auto calc1 = computeSomeValue1();
auto calc2 = computeSomeValue2();
auto divisor = computeDivisor(calc1, calc2);
// danger! ref to divisor will dangle!
filters.emplace_back( [&](int value) { return value % divisor == 0; } );
}
哪怕使用显示地具名引用捕获,也会产生同样的问题
// Still in funtion addDivisorFilter
// danger! ref to divisor will still dangle!
filters.emplace_back( [&divisor](int value) { return value % divisor == 0; } );
Scott Meyers还提到,哪怕创建的lambda马上就会使用,也不准备复制它,那么有人觉得隐式的引用捕获就不会有提到的引用悬空的问题。
Scott Meyers的建议是,因为这样的lambda也许会在之后认为是有用的,而且可以被用到其他的地方,所以可能会被单独复制出来放到别的地方(比如容器里面)去使用,这时候就又回到了之前所提到的引用悬空的问题上了。
所以Scott Meyers说,像这样的情况,最好显示地把lambda要捕获的变量或参数列出来,防止意外发生。
而针对上面的引用悬空的问题,就使用值捕获的办法,而且不是隐式的值捕获。
隐式的值捕获也可能造成“悬空”
Scott Meyers也提到了,(隐式的)值捕获也不是消除“悬空”问题的灵丹妙药。
他以下面的例子做了说明。
class Widget {
public:
/* ... */ // ctors, etc.
void addFilter() const; // add an entry to filters
private:
int divisor; // used in Widget's filter
};
void Widget::addFilter() const {
filters.emplace_back( [=](int value) { return value % divisor == 0; });
}
这个Widget::addFilter乍一看好像没问题,使用了隐式的值捕获,好像是要捕获成员变量divisor,但实际上问题就在这里:lambda只捕获局部变量和参数,不捕获static和成员变量。而这里divisor就是成员变量,它是不能捕获的。
一旦写成下面的两种形式,编译就会失败
// Failure example 1: no local divisor available
void Widget::addFilter() const {
filters.emplace_back( [](int value) { return value % divisor == 0; });
}
// Failure example 2: no local divisor available
void Widget::addFilter() const {
filters.emplace_back( [divisor](int value) { return value % divisor == 0; });
}
上面的第一种写法,没有捕获变量或引用,所以找不到divisor。
上面的第二种写法,目的是为了捕获divisor,但divisor不是局部变量,而是成员变量。根据lambda不捕获成员变量的规则,所以找不到divisor。
可上面[=]这样写的这段代码又确实可以编译,为什么?因为(隐式)捕获的值实际上是this指针。
实际上Widget::addFilter里面的lambda等价于下面的代码
void Widget::addFilter() const {
auto cptr = this;
filters.emplace_back( [cptr](int value) { return value % cptr->divisor == 0; } );
}
所以,捕获的实际上是this指针。而且正因为这样做捕获了this指针(值捕获),就带来了潜在的风险。
比如有下面调用函数Widget::addFilter的代码
using FilterContainer = std::vector<std::function<bool(int)>>; // as before
FilterContainer filters; // as before
void doSomeWork() {
auto pw = std::make_unique<Widget>(); // create Widget
pw->addFilter(); // add filter that uses Widget::divisor
/* ... */ // other operations
} // destroy Widget; filters now holds dangling pointer!
就像注释里面提到的,因为lambda捕获的是this指针(值捕获),所以这个std::vector里面存储的closure里面包含的实际上是一个this指针,而当那个this指针所指向的对象(由std::unique_ptr管理)被销毁了之后,再去访问和调用容器里面存储的closure时,问题就出现了:存储的this指针实际上已经“悬空”了。
要解决这个问很简单,把要使用的成员变量拷贝到一个局部变量上,然后让lambda值捕获即可。
void Widget::addFilter() const {
auto dvs = divisor; // copy data member
filters.emplace_back( [dvs](int value) { return value % dvs == 0; } );
}
值捕获的lambda也不是自成一统
原因就是,lambda不会捕获static变量,不论是class的static还是文件的static变量。
Scott Meyers再次强调了,lambda只捕获non-static的局部变量和参数。
还是前面同样的例子:向一个全局的容器里添加closure。
using FilterContainer = std::vector<std::function<bool(int)>>; // as before
FilterContainer filters; // as before
void addDivisorFilter() {
static auto calc1 = computeSomeValue1(); // now static
static auto calc2 = computeSomeValue2(); // now static
static auto divisor = computeDivisor(calc1, calc2);// now static
// captures nothing! refers to above static
filters.emplace_back( [=](int value) { return value % divisor == 0; } );
++divisor; // modify divisor
}
上面的代码中,因为divisor已经变成了函数的static变量,所以实际上[=]什么也没有捕获,所以lambda生成的closure里面使用的divisor是一个static的变量,等到这个closure实际被调用的时候,divisor的值也许早都变了!
这个例子也同时说明了,哪怕是用值捕获,有时候,lambda也不是自成一体,独立于其他变量之外的。
Things to Remember
Default by-reference capture can lead to dangling references.
Default by-value capture is susceptible to dangling pointers (especially this), and it misleadingly suggests that lambdas are self-contained.
Item 32: Use init capture to move objects into closures.
C++11的lambda不支持移动捕获
C++14支持、但C++11不支持以下两种情况
把只能move的对象放入closure中,比如
std::unique_ptr,std::future等。把move比copy更高效的对象放入closure中,比如STL中的容器。
这两种情况都是所谓的移动捕获(move capture)。
有一些workaround能使得C++11把一个对象“移动”入一个closure中。
C++11中缺少移动捕获(move capture)被认为是一个缺点,C++14做了弥补。但移动捕获只是C++14中捕获机制的一项。
C++14中引入的机制叫做 init capture(又叫做 generalized lambda capture),C++11能做的它都能做,而且能做的更多。但init capture不支持default capture mode(尽管前面一节讲了应该避免这种捕获模式)
使用 init capture 可以使我们明确指明
lambda生成的closure中的数据成员的名字
用来初始化那个数据成员的表达式
the name of a data member in the closure class generated from the lambda and
an expression initializing that data member.
C++14移动捕获示例
假如有一个class,打算创建一个它的std::unique_ptr,并把它移入一个lambda中。
class Widget { // some useful type
public:
bool isValidated() const;
bool isProcessed() const;
bool isArchived() const;
private:
/* ... */
};
下面是创建一个std::unique_ptr,并把它移入一个lambda中(C++14的移动捕获)。
auto pw = std::make_unique<Widget>(); // create Widget
/* ... */ // configure *pw
// Create a lambda
auto func = [pw = std::move(pw)] // init data mbr in closure w/ std::move(pw)
{ return pw->isValidated() && pw->isArchived(); };
在C++14的移动捕获中,等号=左边的pw是closure里面的数据成员,而等号=右边的是用来初始化它的表达式。
其中,等号=左边的pw,它的作用域是在closure中,而等号=右边的pw(std::move中)的作用域是和lambda所定义的作用域一致。这两个是不同的变量。
换句话说,是在closure中创建一个数据成员pw,并用移动了一个当前局部变量pw的结果去初始化它。
So
pw = std::move(pw)means “create a data memberpwin the closure, and initialize that data member with the result of applyingstd::moveto the local variablepw.”
如果不需要修改创建的局部变量pw的话,那么lambda表达式就可以直接写成如下的形式
// In C++14 style
// init data mbr (pw) in closure w/ result of call to make_unique
auto func = [pw = std::make_unique<Widget>()]
{ return pw->isValidated() && pw->isArchived(); };
因为C++11中lambda没有办法捕获一个表达式,而C++14可以,所以这种捕获更一般化,所以 init capture 也叫做 generalized lambda capture。
C++11实现“移动捕获”的办法(用类)
lambda expression的本质实际上是:用一种简便的办法,让编译器创建一个类,并创建一个类的对象。
所以,lambda能做的,你都能做。
There is nothing you can do with a lambda that you can’t do by hand.
下面是以C++11的方式,通过创建类的办法,把上面的C++14的lambda代码做了实现(实际就是创建了类和类的对象)
class IsValAndArch { // "is validated and archived"
public:
using DataType = std::unique_ptr<Widget>;
// Use of std::move
explicit IsValAndArch(DataType&& ptr) : pw(std::move(ptr)) {}
// Define a callable operator
bool operator()() const { return pw->isValidated() && pw->isArchived(); }
private:
// A data member for capture
DataType pw;
};
// Create an object of that class, using move ctor
auto func = IsValAndArch(std::make_unique<Widget>());
注意,创建的operator()()是const的specifier。
C++11实现“移动捕获”的办法(用std::bind)
在C++11中如果想实现移动捕获,除了创建类和类的对象,如果想仍然使用lambda的形式,就要用到std::bind。这个办法分两步
(1)使用
std::bind创建一个function object,并且把需要移动捕获的对象移动到这个function object中(2)需要给lambda表达式一个引用来指向被捕获的对象
例如,有一个局部的std::vecotor,放入了一些数据,然后把它移动到一个closure中,C++14的lambda是
std::vector<double> data; // object to be moved into closure
/* .. */ // populate data
auto func = [data = std::move(data)] { /* uses of data */ }; // C++14 init capture
而C++11使用std::bind,代码实现变为
std::vector<double> data; // object to be moved into closure
/* .. */ // populate data
// C++11 emulation of init capture
auto func = std::bind( [](const std::vector<double>& data) { /* uses of data */ },
std::move(data));
和lambda类似,std::bind也会生成一个function object(可调用的函数对象),Scott Meyers把这个function object叫做 bind object。
std::bind第一个参数是一个可调用的对象(实际上就是重载了operator()()),后面的参数是传递给那个可调用对象的参数。
传递给std::bind的参数都是被拷贝到所谓的bind object(Scott语)中去的。如果是左值参数,bind object中的对象就是拷贝构造出来的;如果是右值参数,bind object中的对象就是移动构造出来的。
上面std::bind的第二个参数是一个右值,所以std::bind生成的bind object中的对象就是移动构造出来的。
当这个std::bind生成的bind object被调用的时候(即调用它的function call operator的时候),存储的在bind object中的参数就依次传递给那个callable object(这个callable object是原先传递给std::bind的第一个参数)。
所以在上面的例子中就是,那个原先的局部变量data被move-constructed存储到了std::bind生成的bind object中,然后调用这个bind object的时候,这个已经存储到bind object中的move-constructed copy of data就被当做参数,传递给了那个保存的callable object,即那个lambda(会生成的closure,把那个参数存到closure里面,也就是说std::bind生成了一个函数对象,它所存储的lambda有再次会生成这个lambda对应的closure,然后把对应的参数存在lambda对应的closure里面)。
因为lambda默认生成的成员函数operator()()是const,即operator()() const,这也意味着这个lambda生成的closure所存储的成员数据就都是const。
而std::bind生成的bind object中存储的move-constructed copy of data不是const,所以为了防止lambda的closure里面的data被修改,就需要把lambda的参数改成reference-to-const。
如果把lambda声明成mutable,那么lambda生成的成员函数operator()()就不再是const了,这样就可以把lambda参数中的const限定去掉
std::vector<double> data; // object to be moved into closure
/* .. */ // populate data
// C++11 emulation of init capture for mutable lambda
auto func = std::bind( [](std::vector<double>& data) mutable { /* uses of data */ },
std::move(data));
因为std::bind生成的bind object,它存储的都是传递给std::bind的参数的拷贝,所以这个bind object也存储了一份lambda生成的closure的copy,所以这个closure就和这个bind object的生命周期一样长。
关于std::bind需要注意的几点
C++11中,不能在closure中移动构造一个对象,但是可以在bind object(
std::bind生成)中移动构造一个对象。在C++11(的lambda)中要模拟实现“移动捕获”的话,需要在一个bind object中移动构造一个对象,然后以引用的方式把那个移动构造的对象当做参数传递给lambda表达式。
因为bind object的声明周期和它所包含的closure的生命周期一样长,所以可以认为那个在bind object中的(移动构造的)对象,就好像在closure中。
最后,如果是C++14捕获表达式,C++11同样可以借用std::bind来实现
// C++14 style capture expression
// as before, create pw in closure
auto func = [pw = std::make_unique<Widget>()] {
return pw->isValidated() && pw->isArchived();
};
// C++11 style to emulate capture expression
auto func = std::bind([](const std::unique_ptr<Widget>& pw)
{ return pw->isValidated() && pw->isArchived(); },
std::make_unique<Widget>() );
Things to Remember
Use C++14’s init capture to move objects into closures.
In C++11, emulate init capture via hand-written classes or
std::bind.
Item 33: Use decltype on auto&& parameters to std::forward them.
C++14 Generic lambda
C++14引入了 generic lambda,它可以在参数前面使用auto关键字。
auto f = [](auto x){ return func(normalize(x)); };
它等价于,由lambda生成的closure class的operator()是一个template函数
class SomeCompilerGeneratedClassName {
public:
template<typename T> // see Item 3 for auto return type (C++14)
auto operator()(T x) const { return func(normalize(x)); }
/* ... */ // other closure class functionality
};
使用auto&&和decltype
前面是个简单的例子,参数x是以值传递的方式传给函数normalize的。但如果函数normalize会按照参数的左值或右值属性分别做处理的话,那么参数x就必须以万能引用的方式进行传递。
下面是一个直观的修改,但不完整。
auto f = [](auto&& x) { return func(normalize(std::forward<???>(x))); };
此时就有问题了,因为x它虽然是万能引用,但它本身是一个具名变量,所以它也是一个左值,所以如果要保留它的左值和右值属性传递给函数normalize的话,就要使用std::forward。
但使用std::forward,就需要指出它的类型T,即写作std::forward<T>。而此时x是以auto&&万能引用的形式给出的,并没有类型T。虽然这个lambda生成的closure class里面的operator()函数的模板参数是T,但那个只有编译器可以看到,写代码时并不能使用。
这种情况下,就可以使用 decltype。
根据item 28中的类型推导的规则,以及引用折叠规则
如果万能引用绑定到一个左值(lvalue),那么
T就被推导为左值引用(如Widget&),同时参数x就是左值引用(即例如Widget& &&==Widget&),即decltype(x)就是左值引用(如Widget&)如果万能引用绑定到一个右值(rvalue),那么
T就被推导为非引用类型(如Widget),同时参数x就是右值引用(即Widget &&==Widget&&),即decltype(x)就是右值引用(如Widget&&)
但是,同样根据item 28中,std::forward的使用惯例,当T是一个左值引用的时候(比如Widget&),那么转发的是一个左值,当T是一个非引用的时候(比如Widget),那么转发的是一个右值。
即,std::forward<Widget&>转发的是左值,而std::forward<Widget>转发的是右值。
那么前面的两种情况分别是decltype(x)为左值引用(如Widget&)和右值引用(如Widget&&),它们分别当做std::forward的模板参数,是否可以?
答案是可以。
原因是可以从std::forward的实现上得出答案。
template<typename T> // in namespace std
T&& forward(remove_reference_t<T>& param) {
return static_cast<T&&>(param);
}
当T是左值引用,比如Widget&时,做简单的直接替换之后,可以发现返回的是左值引用(代码略)
当T是非引用类型时,比如Widget时,做简单的直接替换之后,发现返回的是右值引用,代码如下。
template<typename T> // in namespace std
Widget&& forward(Widget& param) {
return static_cast<Widget&&>(param);
}
当T是右值引用时,比如Widget&&时,做简单的直接替换之后,发现返回的是右值引用,代码如下。
template<typename T> // in namespace std
Widget&& && forward(Widget& param) {
return static_cast<Widget&& &&>(param);
}
上面的代码经过引用折叠得到
template<typename T> // in namespace std
Widget&& forward(Widget& param) {
return static_cast<Widget&&>(param);
}
所以,其实当std::forward的模板参数T是非引用类型或右值引用的时候,返回的都是右值引用。(当T是左值引用时,返回的是左值引用)
因此,根据这个结论,decltype(x)是可以当做C++14 lambda里面的完美转发的模板参数的,即上面的例子可以写作
auto f = [](auto&& x) { return func(normalize(std::forward<decltype(x)>(x))); };
由于C++14的lambda也支持 variadic lambda,所以它也可以支持多个参数的万能引用和完美转发
auto f = [](auto&&... params) {
return func(normalize(std::forward<decltype(params)>(params)...));
};
Things to Remember
Use
decltypeonauto&¶meters tostd::forwardthem.
Item 34: Prefer lambdas to std::bind.
本节的主要目的是说明
在C++14中,lambda可以做到
std::bind能做到的一切,而且会做的更好,所以在C++14中应该使用lambda在C++11中,只有两种情况lambda做不到(move capture和templatized function call object),需要使用
std::bind来代替,其他情况下,都应该使用lambda
C++11/14的lambda比std::bind更有可读性
C++11和C++14中,lambda比 std::bind更好的原因之一就是,可读性强。
The most important reason to prefer lambdas over
std::bindis that lambdas are more readable.
举例,有个函数setAlarm来设定一个可发声的警报。
// typedef for a point in time (see Item 9 for syntax)
using Time = std::chrono::steady_clock::time_point;
// see Item 10 for "enum class"
enum class Sound { Beep, Siren, Whistle };
// typedef for a length of time
using Duration = std::chrono::steady_clock::duration;
// at time t, make sound s for duration d
void setAlarm(Time t, Sound s, Duration d);
我们需要设置它,并于设置1小时之后,发出警报,持续30秒,但是发出的声效是待定的(作为参数)。
如果改用lambda的形式(C++11),就可以只用输入一个参数,即指明发出的声效。
// setSoundL ("L" for "lambda") is a function object allowing a sound to be specified
// for a 30-sec alarm to go off an hour after it's set
auto setSoundL = [](Sound s) {
// make std::chrono components available w/o qualification
using namespace std::chrono;
setAlarm(steady_clock::now() + hours(1), // alarm to go off
s, // in an hour for
seconds(30)); // 30 seconds
};
如果使用C++14的lambda形式会更简单
// setSoundL ("L" for "lambda") is a function object allowing a sound to be specified
// for a 30-sec alarm to go off an hour after it's set
auto setSoundL = [](Sound s) {
// make std::chrono components available w/o qualification
using namespace std::chrono;
using namespace std::literals; // for C++14 suffixes
setAlarm(steady_clock::now() + 1h, // alarm to go off
s, // in an hour for
30s); // 30 seconds
};
如果使用std::bind来实现上面的lambda,一个简单(但存在问题)的转换如下
using namespace std::chrono; // as above
using namespace std::literals;
using namespace std::placeholders; // needed for use of "_1"
auto setSoundB = std::bind(setAlarm, // "B" for "bind"
steady_clock::now() + 1h, // incorrect! see below
_1,
30s);
首先,这个实现的可读性显然没有lambda的好。_1代表我们在调用setSoundB这个bind object时传给它的参数,而这个参数实际上是作为setAlarm的第二个参数传入的。
其次,这个实现存在问题。在std::bind的实现中,steady_clock::now() + 1h是作为std::bind的参数传给它的,这就意味着当执行了std::bind(...)之后,这个时间就已经做了计算,而此时setSoundB还没调用!换句话说,我们希望这个警报是在我们设置1小时之后发声,而不是在std::bind起1小时之后发声。
为了解决第二个问题,需要用到C++14中的std::plus,以及一个嵌套的std::bind。
auto setSoundB = std::bind(setAlarm,
std::bind(std::plus<>(), steady_clock::now(), 1h),
_1,
30s);
如果使用C++11中的std::plus,上面代码的等价形式是
auto setSoundB = std::bind(setAlarm,
std::bind(std::plus<steady_clock::time_point>(),
steady_clock::now(),
hours(1)),
_1,
30s);
显然,不论是C++11还是C++14中的lambda,都比std::bind更具有可读性。
当需要绑定重载函数时,lambda比std::bind更有可读性
假设除了前面提到的,接收3个参数的函数setAlarm,如果还有一个重载函数setAlarm,它有第4个参数用来指明音量。
enum class Volume { Normal, Loud, LoudPlusPlus };
void setAlarm(Time t, Sound s, Duration d, Volume v);
如果使用lambda,显然很容易,因为编译器可以找到对应的重载函数
auto setSoundL = [](Sound s) { // same as before
using namespace std::chrono;
setAlarm(steady_clock::now() + 1h, // fine, calls
s, // 3-arg version
30s); // of setAlarm
};
但是如果还是使用之前的std::bind的形式,编译就会失败,因为编译器知道的只有一个函数名字,无法知道选择哪一个重载函数。
// error! which setAlarm?
auto setSoundB = std::bind(setAlarm,
std::bind(std::plus<steady_clock::time_point>(),
steady_clock::now(),
hours(1)),
_1,
30s);
所以如果还是使用std:bind的话,需要进一步做如下的修改
// setAlarm must be cast to the proper function pointer type
using SetAlarm3ParamType = void(*)(Time t, Sound s, Duration d);
// Cast to correct func ptr to let compiler know which overload to choose
auto setSoundB = std::bind(static_cast<SetAlarm3ParamType>(setAlarm),
std::bind(std::plus<steady_clock::time_point>(),
steady_clock::now(),
hours(1)),
_1,
30s);
上面的lambda和std::bind的实现,会导致最后调用的时候产生一个可能的潜在差异。
使用lambda的话,因为lambda直接调用了setAlarm,所以编译器通常会inline。
而使用std::bind的话,使用的是一个函数指针,编译器通常对函数指针调用的函数不做inline。
所以使用lambda更有效率。
std::bind比lambda更难写的另一个例子
假如有一个lambda用来检查一个整数是否在指定的范围之内
// C++14
auto betweenL = [lowVal, highVal] (const auto& val)
{ return lowVal <= val && val <= highVal; };
// C++11, because auto cannot be specified, so specify the type explicitly
auto betweenL = [lowVal, highVal] (int val)
{ return lowVal <= val && val <= highVal; };
但如果使用std::bind,写起来就复杂不少
using namespace std::placeholders; // as above
// C++14
auto betweenB = std::bind(std::logical_and<>(),
std::bind(std::less_equal<>(), lowVal, _1),
std::bind(std::less_equal<>(), _1, highVal));
// C++11, we’d have to specify the types we wanted to compare
auto betweenB = std::bind(std::logical_and<bool>(),
std::bind(std::less_equal<int>(), lowVal, _1),
std::bind(std::less_equal<int>(), _1, highVal));
std::bind保存了参数的值还是引用?
假如有个用来压缩一个Widget对象的函数compress,可以指定压缩程度
enum class CompLevel { Low, Normal, High }; // compression level
Widget compress(const Widget& w, CompLevel lev); // make compressed copy of w
如果对于一个固定的Widget,写一个std::bind来指明需要压缩的程度
Widget w;
using namespace std::placeholders;
auto compressRateB = std::bind(compress, w, _1); // "B" is short for Bind
compressRateB(CompLevel::Noraml); // Call compressRateB
这时候的问题是,w是被当做参数传递给了std::bind生成的bind object,但它保存的是参数的引用,还是值?
保存方式的不同会导致潜在的差异,原因是,如果保存是引用,那么调用了compressRateB之后,原先的w就会被修改;而如果保存的是值,那么调用了compressRateB之后,原先的w并不会发生改变。
答案是:std::bind保存的是值(stored by value)。
All arguments passed to bind objects are passed by reference.
可以看出,除非指定std::bind的工作机制,否则就不知道其参数的变化。
除此之外,传给std::bind生成的bind object的参数,是值传递还是引用传递?
如果使用lambda,情况就一眼可以看清楚,而使用std::bind的bind object调用,还是得清楚std::bind的机制
// w is captured by value; lev is passed by value
auto compressRateL = [w](CompLevel lev) { return compress(w, lev); };
compressRateL(CompLevel::High); // arg is passed by value
compressRateB(CompLevel::High); // how is arg passed? Answer is by reference
std::bind的参数都是按引用传递的(passed by reference)
C++11中有两种情况不得不用std::bind代替lambda
从上面的讨论可以得知
C++14,能用lambda就用lambda,不要使用
std::bind,因为lambda可以做std::bind能做的全部,而且做的更好。C++11,只有两种情况需要使用
std::bind,其他情况使用lambda更好。这两种情况是Move capture(需要移动捕获的时候,item 32讲述了原因)
Polymorphic function objects(多态函数对象?)
C++11中需要使用std::bind的第一点,在item 32中已经讲述了。
关于第二点,因为bind object的function call operator(operator)使用的参数是万能引用(完美转发),使用它可以接收几乎任何参数类型。所以如果需要绑定的是a templatized function call operator,这时候C++11中的lambda就不能使用了,但可以使用std::bind来解决这个问题。
下面这个例子,是一个class有operator(),但它同时是一个模板函数。
class PolyWidget {
public:
template<typename T>
void operator()(const T& param);
};
使用std::bind来绑定一个PolyWidget对象,然后调用如下
PolyWidget pw;
auto boundPW = std::bind(pw, _1);
boundPW(1930); // pass int to PolyWidget::operator()
boundPW(nullptr); // pass nullptr to PolyWidget::operator()
boundPW("Rosebud"); // pass string literal to PolyWidget::operator()
如果使用C++11的lambda,是办不到这件事情的。
但如果使用C++14的lambda,是可以做到的。(使用auto)
// C++14
auto boundPW = [pw](const auto& param) { pw(param); };
Things to Remember
Lambdas are more readable, more expressive, and may be more efficient than using
std::bind.In C++11 only,
std::bindmay be useful for implementing move capture or for binding objects with templatized function call operators.